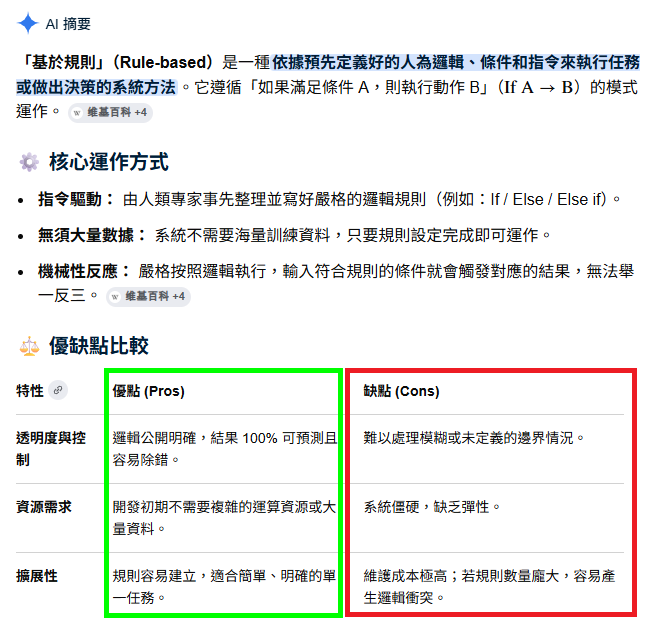
我的影像辨識技術確實就是合乎Rule based的概念,我之前比較習慣稱之為「專家系統」的AI!剛好與客戶互動時他提到這個名詞,我就請Google幫我解釋一下,Google就如上這麼說的!我覺得他說的優點全對,但是缺點幾乎全是錯的!應該都是出於機器學習派的惡意誤導與偏見!
常來此地的讀者都知道,我的車牌辨識在模糊辨識的能力方面是十分傑出的!哪有「難以處理模糊或為定義的邊界狀況?」我如何做到的?我也都在每篇文章中詳細說明了!基本上是盡量引用非影像的客觀知識,或是做一些以影像資料為基礎的局部資料統計!機器學習可以依據資料統計自我調整,我也可以的!還是由專家親自監督寫成明確邏輯的,只會更快完成還更加準確!
簡單說,並不是使用Rule based之後就不能使用類似機器學習的統計概念或嘗試錯誤來優化系統的!所以「系統僵硬,缺乏彈性」也是胡說八道!屬於刻意醜化或惡意栽贓,以此凸顯機器學習的相對優勢?但是根本沒有這個無謂的限制,我的Rule based軟體也是可以隨時使用機率統計的概念優化系統的!
至於「維護成本極高」也是匪夷所思的惡意誤導錯置!這反而是相對競爭的機器學習最大的缺點!Rule base的軟體是依據明確邏輯建立的精密儀器,極少無謂的計算,如果出錯時因為邏輯明確,也都能立即分析演算過程,找到錯誤迅速修正處理,所以這種軟體的維護成本極低!
機器學習的模式就剛好相反!計算量會大到無法在一般規格的電腦上執行,所以必須使用GPU來救災!光是電腦硬體設備的成本就高上很多!辨識錯誤時也完全無法進行簡單直接準確的維護修改,必須用更大量的資料重新訓練系統,維護成本就更是高得嚇人了!這就是以機器學習派的立場顛倒是非惡意侮蔑Rule based系統了!
至於「邏輯規則數量龐大,容易產生邏輯衝突」是Googl AI提出的唯一堪稱正確,合乎我的影像辨識開發經驗的小缺點!也是使用Rule based的方式開發軟體最大的成本!你必須真的有專業知識充足的專家來執行整合、測試與調整這些潛在的邏輯衝突!這也就是我現在日常的工作!這需要很好的專業知識,但是實作並不困難。
現在大家都擔心AI會搶走很多人的工作,如果機器學習真的那麼神奇完美?確實非常多工作就會被取代,為何影像辨識會被CNN與深度學習等技術大舉入侵?原因就是使用那些技術就不必找到真正的理解影像辨識原理的專家來主持了,任何人只要上過幾節AI課,會使用那些工具模組程式就可以開工了!
但是我相信大家終究必須面對機器學習的諸多缺點,就是沒有真正專業影像辨識知識的協助,他們永遠無法達到高辨識率的目標!研發成本的居高不下也會形成極大的壓力!你可以用砸錢的方式快速得到初步的成果,但是永遠無法達到終極目標!反觀Rule based的方式則迅速有效得多!
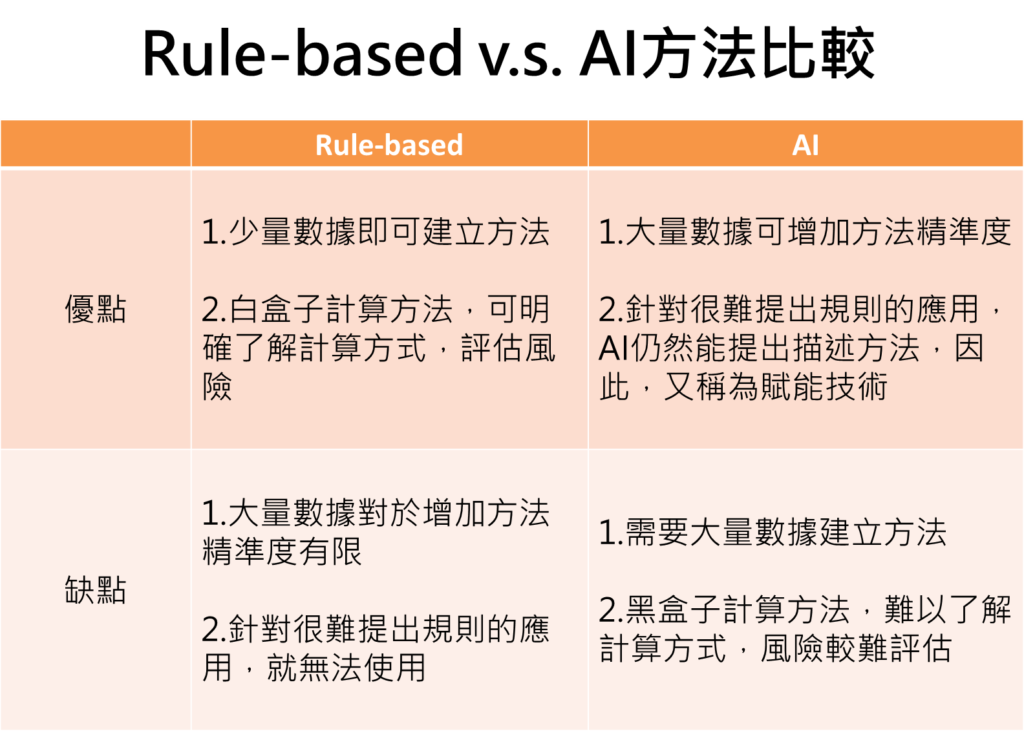
下面是Rule-based v.s. AI方法比較這篇文章的圖示,我覺得非常中肯,值得大家參考!尤其是他的結論說:有些情境下,還可同時結合兩種方法來做描述,互相補足兩者不同的地方,在場域應用上發揮最大成效。就正好是我對影像辨識的作法!以Rule-based為基本架構,在模糊難以決策的部分使用CNN與機器學習的統計學概念技術作為補強,讓我兼得了兩種技術概念的優勢!所以做AI其實不必二選一的!











限會員,要發表迴響,請先登入


