
英數字元要看得清晰自然,通常1與I先天就是比較窄的!甚至為了看得清楚一些,M與W還會特別寬!如果「字間」的距離保持一樣,就會顯得某些字與字之間的中心距離變得不一樣了!一般文件上出現的印刷體字大概都是這樣的!但是如果車牌也這樣設計其實是會造成辨識困難的!
如果你是用我的OCR辨識方式,字元影像也很清晰,每個字都能一次就確定大小範圍那就還好!但是如果你試圖用CNN的方式掃描找到正確的字元就尷尬了!因為你必須假設目標是一個矩形,甚至必須是個正方形!但是字元就是有寬有窄,使用「標準字元大小」的矩陣掃描字寬較窄的 1 或 I 時,一定會包含相鄰字元的一部份!
即使是我用OCR辨識字元,如果字元沾連或破碎時,我也必須用目標之間的距離判斷它們是不是分裂或沾連的目標?此時我可以仰賴的標準就是字寬與字距(目標中心點間的距離)了!如果字寬與字距都不保證一樣,我就會非常困擾了!所以新型的車牌設計字距都是一樣的!通常字寬也會盡量設計成等寬!如下圖的 1 可以變成一個底部特別寬的字,這樣字寬就與其他字一樣了,也不會因此誤認為別的字!
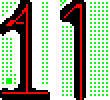
這種刻意的改變就是為了讓車牌辨識較容易執行的設計!但是已經上線使用超過數十年的舊型車牌就有較多歷史的包袱,不是說改就能改的!我們這些研究車牌辨識的人當然只能盡量設法從演算法的特殊設計上解決這些問題了!理論上來說 CNN使用者因此產生的困擾會比我的OCR大很多!所以他們的車牌定位都沒問題,辨識車牌的內容時則遠不如OCR準確穩定!
台灣車牌的字寬是1與I比其他字窄的,但至少字距是大致一樣的,新加坡的車牌就是既不等寬又不等距的最麻煩狀況,很多歐美車牌都是這樣的!所以並不是越先進早發展科技的國家車牌就越好辨識!五十年前設計的車牌是給人眼看的,不會考慮到影像辨識的難易!反而是較晚出現車牌的越南或柬埔寨車牌都超好辨識!他們都預設是要給電腦辨識的嘛!
類似的辨識考慮也包括會避免使用英文的 I 與 O 字!這一點我們台灣的七碼車牌與新加坡車牌都有考慮到的!柬埔寨的車牌則是將O字設計成很特別的形狀如下圖:
















限會員,要發表迴響,請先登入


