有些狀況字模辨識就是不夠的!需要有創意的特徵辨識!
2026/06/20 04:43
瀏覽1,032
迴響0
推薦15
引用0

理論上,如果所有車牌製作都嚴謹按照監理單位的規定,使用完全一致的標準字型,而且拍攝影像永遠可以正面清晰,那麼使用字模比對的方式一定就可以正確辨識出目標是甚麼字了!但現實世界當然沒有這麼完美,像上例的G很容易就會被誤認為C了!
真的只差一點點,新加坡車牌也沒有為G與C做出誇張的差別字型,即使有!也不保證車牌製作業者會守規矩完全正確使用。如果有誤認我們也不能去告發車牌製作業者的!我們必須追求的目標是不讓出錢要我們做辨識的客戶抱怨!他們會抱怨甚麼呢?就是我的軟體辨識能力不能比他的人眼辨識還差!
此時我們就應該問:為什麼像上面這種其實G與C很像的狀況,絕大部分視力正常的人還是會靠「直覺」認定那個字是G而不是C呢?其實這就不是完全靠字元整體的形狀,而是局部的特徵了!我的研究結果就如下圖,五個其實不太一樣的G都是從實際案例中抓出來的!他們都有個一樣的特徵!
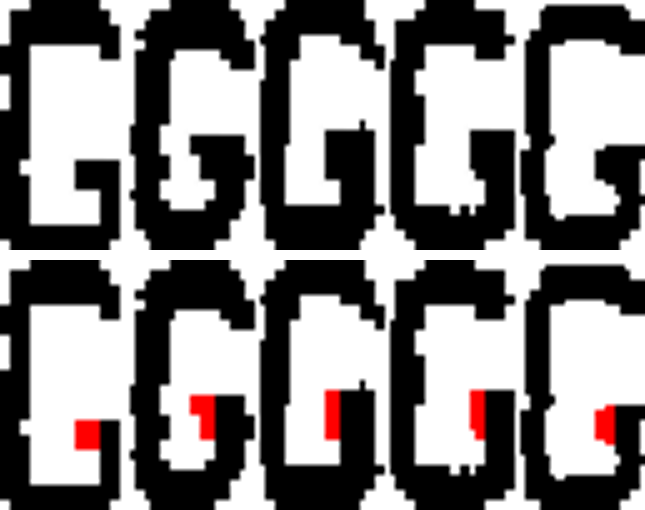
就是紅色標記部分的細微轉折,只要我們的眼睛有看到這個特徵,不管這個曲折部分有多小,都會讓我們認為這一定是個G了!既然如此,我想讓我的軟體有一樣的判斷能力,就是要設法寫出辨認有沒有這個特徵的程式了!我當然寫出來了才會在此說嘴!我的很多較模糊辨識就是利用這類有創意的特徵辨識趨近人類視覺的!
此時當然要照例吐槽,請問機器學習或深度學習大師們:你們需要多少資料?多大的訓練量?才能訓練出這種精緻聰明的AI判斷能力呢?即使你們「有可能」做出一樣聰明的辨識軟體,成本也會高到你們絕對不願意公開討論的程度!這就是使用ML、DL與CNN等技術製作影像辨識軟體的罩門了!效率實在太低,成本也真的太高了!完全不切實際的!













你可能會有興趣的文章:
限會員,要發表迴響,請先登入


