這是我問Google AI影像辨識與GPU相關性時出現的答案!因為影像資料本來就是比其他數位資料的資料量大很多!一個字元只需要兩個Byte儲存,即使是中文字或任何國家語文的字元!所以一本小說的純文字檔案可能不到1M!語音資料是一個一維的數字時間序列也不算太大,影像資料不但是二維陣列,每一個位置(畫素)還有至少三種顏色(RGB)的資訊,百萬畫素的影像就有幾百萬(很多M)個Byte的資料量!
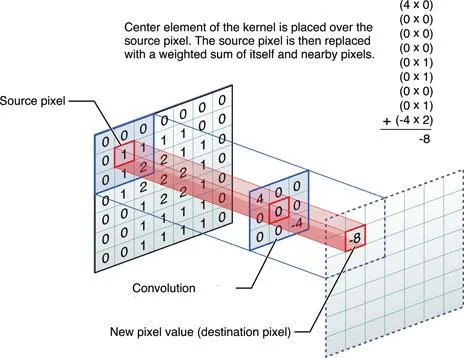
但是GPU對於影像辨識會變得如此重要?主要原因並不是影像資料本身的龐大,而是CNN(類神經網路)的演算概念是以矩陣運算為基礎,用一個3 X 3的矩陣遮罩掃描全圖,就需要影像資料點數的9倍計算量!百萬畫素影像就需要9百萬次計算,11 X 11的矩陣就需要121百萬次(一億兩千一百萬次)的計算!這只是一個步驟的計算量而已,影像辨識會有很多個步驟的,總計算量就更驚人了!
所以只要你用了CNN作為影像辨識的第一步!那就是一條不歸路了!計算量一定會大到讓CPU難以負荷,就必須使用GPU了!所以CNN的演算概念已經出現數十年了,但直到十幾年前才開始被較普遍使用,原因就是計算量大到以往的電腦根本無法在合理時間內執行完成!
但是影像辨識的商業軟體如車牌辨識或指紋辨識已經出現且被使用數十年了!至少十年之前這些軟體顯然不是使用CNN的!否則不可能在二三十年前的電腦上運作的!如果只是為了辨識車牌而使用幾百幾千萬元的NASA用的超級電腦也是不合理的!那他們是怎麼作到的呢?答案就是OCR的傳統影像辨識技術了!
重點是:OCR是不用矩陣掃描運算的!就是將影像簡化成黑白圖,稱之為二值化,再切割成獨立目標,以此為辨識作業的前處理基礎的!就是因為不需要矩陣運算,從原始畫素到判斷它是黑或白?計算量就不會是資料量的幾十甚至幾百倍,頂多只是兩三倍而已!所以速度快上CNN數十到數百倍!這個事實你知道嗎?我是從來沒在網路相關資訊上看到!但我自己就在使用所以我真的知道!
我的影像辨識技術就是從OCR技術開始的!我也以此技術開發車牌辨識商品創業!最近十幾年間CNN開始普及流行,我當然非常關注!如果任何新技術可以替我的產品研發加分,我一定會毫不猶豫立即採用的!能做出好產品賣得出去賺得到錢才是最重要的!我已經不是教授了,學術觀點的爭辯對我毫無意義。
事實上使用CNN的概念寫程式不會比OCR困難,但是一使用就會發現速度實在超級的慢!也就是運算量大到不合理!連研發速度都會因為程式跑得慢而延誤,做出來的軟體太慢也不符合車牌辨識必須即時反應的市場需求,所以我始終沒有真的把CNN當作我的主要處理程序!最多只用於解決關鍵局部模糊區域的強制辨識!使用區域很小就不會太耗時了!
但是無疑的CNN辨識多樣化特徵的量化評估能力是OCR無法做到的!如果我想避免使用CNN,但還是可以達到較複雜辨識能力的效果,我的OCR就必須有所突破!事實上就是我會用多個內容不同的OCR程序來取代,譬如CNN可以一次評估計算出從暗淡到濃烈,甚至互相沾連的所有字元,但是一次的OCR只能有一個門檻,參數不同切割出來的結果就可能不同,某些字就會遺漏了!
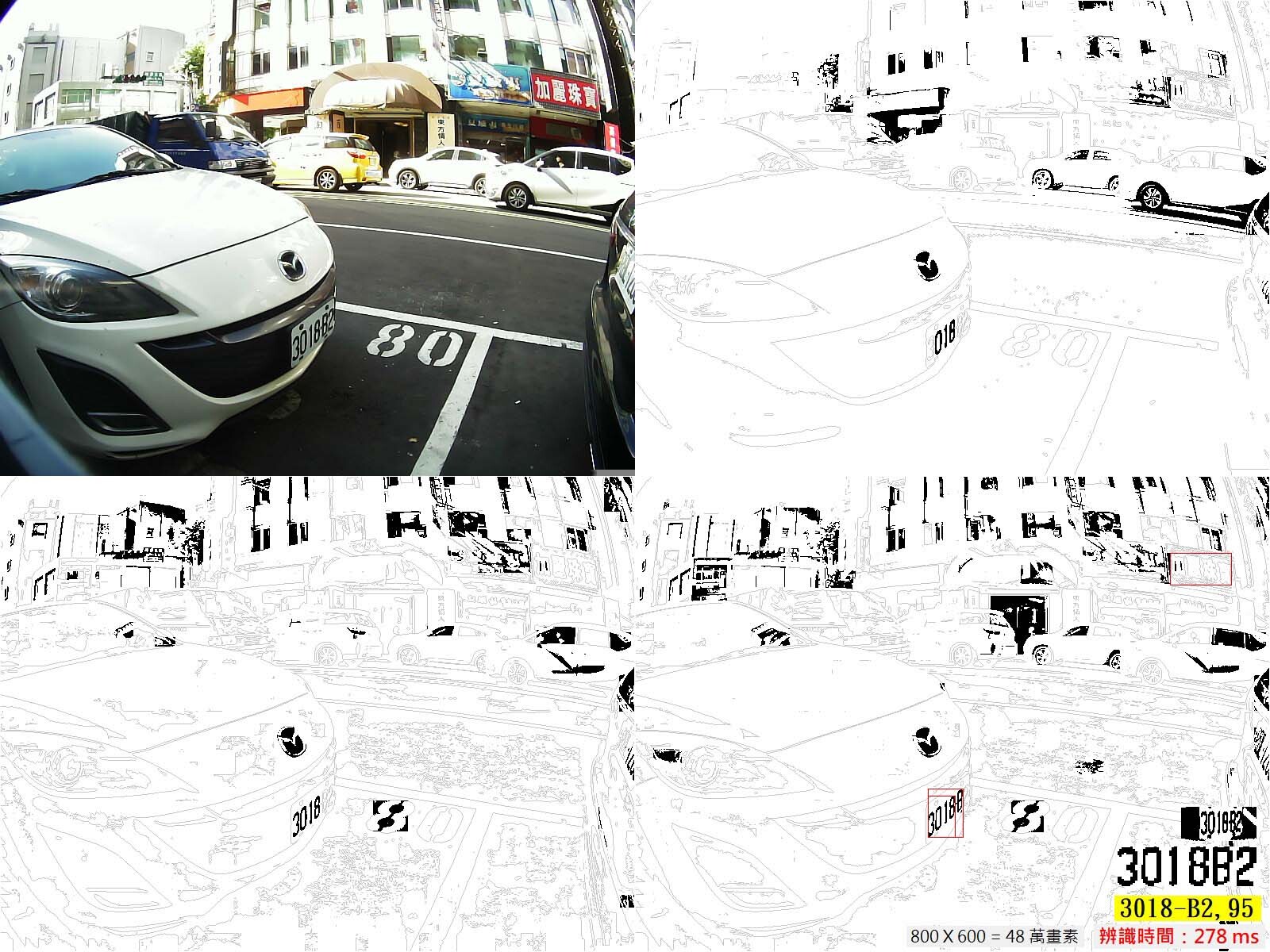
我的解決方式就是用多次的OCR辨識流程,嘗試取代極為耗時的CNN特徵搜尋程序!重點是即使我做了好「多次」的OCR辨識,辨識時間(計算量)還是遠遠少於使用「一次」CNN!所以我的軟體才不需要GPU的!如上面的案例,我是做了三次OCR才得到我要的合理車牌答案,事實上還是少了一個字元,是我啟動CNN的方法局部搜尋補上最尾端的2字的!聽起來似乎很繁複?但即使如此總運算量還是在合理範圍,不需要GPU就可以在合理時間278毫秒內完成。
也因此我才會一再強調我是不用CNN也不用GPU的!我想讓大家知道我的影像辨識產品與市場宣稱使用的主流技術有所區隔!而且不是因陋就簡,是真的比較好!除了介紹說明很多歪斜模糊車牌的辨識方法與案例,在此則是讓大家知道想使用影像辨識時,確實有不必使用耗時的CNN,與昂貴的GPU的選項!

另一方面,我會盡量避免使用CNN的原因也跟上面這個理念有關!使用電腦軟體你以為只是按下一個按鍵而已嗎?事實上每次執行一個影像辨識就可能是幾億次的計算!使用不同的演算法解決一樣的問題,實際計算次數的差異可以是幾十幾百到幾千倍!如果只是用GPU加速讓這些無形的能源浪費變得無感?那不就很像運動員吃禁藥來增加體能嗎?贏得比賽的代價是身體崩壞,很恐怖的!你有想過嗎?我知道!所以有在盡力避免,至少在拖延這種地球面臨的大災難!













限會員,要發表迴響,請先登入


