這是一個很好的案例,說明影像模糊時要辨識正確,背後需要多少的努力!現在的機器學習或深度學習都騙你說:再複雜的困難辨識,只要收集夠多資料,讓機器自己訓練學習就行了?但這只是浪漫的幻想!這種事從來沒發生過!創業之初我就擔心深度學習的影像辨識會搶走我的飯碗,十年後的事實卻是我搶了他們的好多碗飯!
我雖然是做生意,靠著研發影像辨識技術謀生的人!但是我也希望把研究成果像學術研究一樣持續發表分享,只是我不當教授了,不必一定要發表在甚麼SCI期刊上而已!我不怕別人模仿抄襲,有句話說:「一直被模仿,但從沒被超越!」其實是個簡單的事實!以高科技產品而言,想要靠模仿超越領先者是幾乎不可能的!除非我已經不再研發了!
簡單說,我用我熟悉的方式跑步,我也認真講解我是怎麼跑的,你學我著我的姿勢跑,或許可以提高原本的速度,但是跟我賽跑是一定會輸的!如果你原本不會的本事,能經過模仿學到就是賺到了!但是想超越本尊呢?那是一個很極高難度的挑戰!所以我從來不怕分享,你不用駭入我的電腦,我沒有商業機密,在此看到的內容比從我的程式看懂學會的更多!
我會想寫出研究成果是基於數十年來的學術訓練與習慣!對於我自己來說就是整理思緒,讓研究脈絡更清晰有條理!每天八成時間做實質研究,兩成時間就是寫文章告訴別人也告訴自己:「我到底在幹甚麼?我做的事情有何價值與意義?」長遠來看,我就是在科技史上留下我的足跡!如果讀者眾多時,甚至可以影響科技的發展方向!那就比當上頂大教授更學術了!
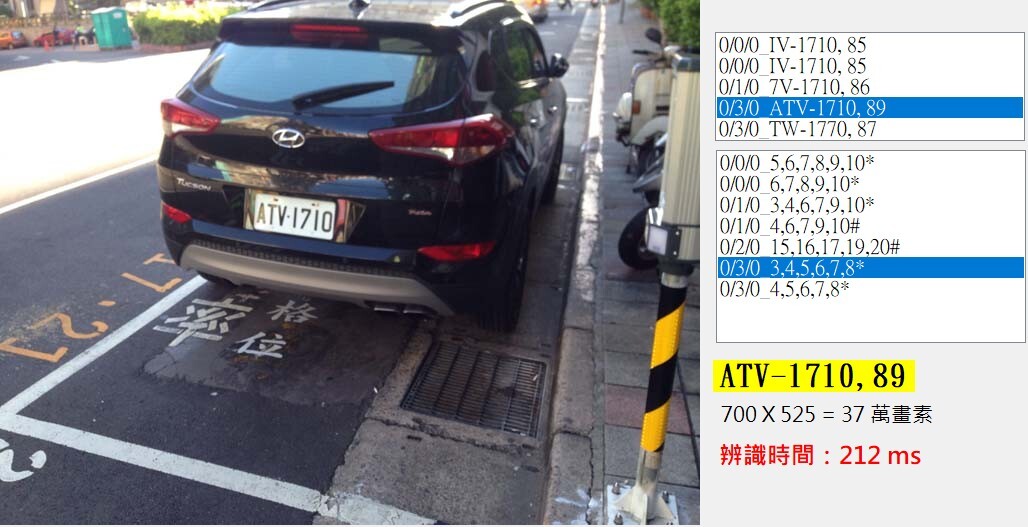
以OCR技術來說,如上的略模糊影像辨識成功的關鍵,就是二值化切割字元的步驟!切割正確時目標字元就可以清晰呈現,如果字元的筆畫與背景色差很大,要正確找到可以區分字元與背景的灰階門檻值機率很大,就沒有甚麼技術可言,如果影像模糊時就是色差不大,甚至每個字的狀況都不太一樣,要正確抓準門檻就難了!
我的作法其實也沒有很神奇,就是建立很多個不同的二值化策略,都嘗試算出該策略下得到的最合理結果,然後就是幾個答案擇優錄取!為了節省時間,當然是以成功機率最大的策略開始,如果估計字元符合度極高,應該不會錯了,就提前結案,類似快速通關結帳的概念!

如上案例就是發現答案的不確定性高,就一共動用了四種二值化策略,產生如上的四種二值化圖,共找到七組可能的車牌目標組合,算出五個可能的車牌答案候選人!取最高89分的答案ATV-1710就是最正確的答案了!這其實就是我常常批評的很「耗時」的嘗試錯誤的運算!也就是機器學習派常用的演算概念!
我當然也想設計出「一種」萬用的二值化策略,在任何狀況下都可以通用!但事實上就是做不到!單一的策略確實可以盡量優化調整(學習訓練?)到一個辨識率最高的極限,超出這個策略的極限時,就必須使用不同的策略才可能得到更合理的答案了!所以機器學習派想訓練出來一個單一模式的萬靈丹,但是不管怎麼作?整體辨識率都一定會輸給我!因為我根本是打群架的!以二值化來說,我內建有六種策略!深度學習怎麼玩得過我?
要這麼作的代價當然就是計算時間可能會增加好幾倍!但是我已經把基礎的運算量極度精簡降到極低了!以上例來說,一個策略算完也只需要幾十毫秒,全部算完也只花212毫秒,還是相當快的!也就是我有本錢在不讓辨識顯得緩慢遲鈍的前提下,適度用更多計算來提高辨識率!
所以我的程式反應是如上大小的影像,容易辨識可以用第一個策略就提前結案時,只需要幾十毫秒!這種狀況約占九成以上!較難辨識必須動用到多個策略才能結案時,就會是一兩百個毫秒了!機器學習或深度學習做出來的單一模型辨識軟體,怎麼作都不會比我的辨識率更好的!你說是誰比較「AI」呢?














限會員,要發表迴響,請先登入


