
我說的「歪斜變形」的車牌是像上圖左這樣的!如果你說的「歪斜車牌」是如上圖右的狀況,那表示你的層級還是相當低的!因為圖右的車牌需要做的幾何校正只是整個車牌的2D處理,就是旋轉→平移→縮放三個步驟而已!圖左的案例如果只是做這些處理,字元只會更極端的倒向左邊而已!就更難辨識了!

所以要做到「自然」情境下的車牌辨識,只有2D的處理技術是不夠的!要把整個車牌旋轉到水平比較容易,基本上就是找到車牌字元組的上或下切線,量出這個基準線的傾斜度據以做影像旋轉即可!結果大概就是上圖的狀況了!這種狀態去比對字模當然是徒勞無功的!所以必須進化到3D變形的處理技術,下圖就是我的軟體可以校正的程度!雖然不算完美,但是已經足以正確辨識是甚麼字了!
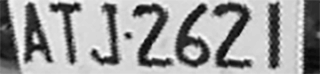
我的車牌辨識10年前推出時就已經可以處理這種變形了!算是很超越時代的技術水準,當時大多數車牌辨識大概傾斜到十度就不行了!下面是大陸華為公司當時的廣告,某次我參加一個南港舉行的大型展覽,刻意去問一家長期承攬台北市政府車牌辨識案的台灣廠商,他們的車牌傾斜最大容忍度是多少?他們的工程師很得意的說可以到15度!我忍不住偷笑喊Yeah!因為我當時的傾斜容忍度就超過45度了!我這個小蝦米在技術上早已輾壓大鯨魚了!
大家或許會問:就是旋轉而已嘛!可以轉10度為何不能轉45度?這是個大哉問!原因出在他們找到車牌的方式還是拘泥於CNN的矩形車牌特徵的搜尋方式!如果影像中的車牌傾斜到二三十度,你還是假設車牌應該大略是個水平的矩形?當然就連車牌都找不到了!前提都錯了當然不會有好結果!
我找到車牌的方式完全不同!我是直接找字元目標的!以目前的高品質影像字元多半是很清楚的!直接用OCR的技術就可以直接找到很多字,而且很快很節省運算量!找到字元之後把相鄰排列整齊的字元群組起來就是車牌了!傾斜度也一併算出來了!不論是傾斜到五六十度都沒差的!說實話,堅持用CNN的矩形架構找車牌真的蠢到不行!速度慢到非請GPU幫忙不可,還找不到歪斜的車牌?但好像除了我之外,大家都是這麼作的!所以我才會一枝獨秀嘛!
但是真正關鍵的技術還是如何知道「字元」的傾斜度,而不只是「車牌」的傾斜度!這兩者在車牌正面直視時當然是互相垂直的!所以傳統車牌辨識演算法中都會認定是同一個參數(dependent)!但是從立體環境中不同的視角看過去,它們就是兩個未必一定互相垂直的獨立變數了!所以才會發生上面案例中車牌都變水平了,還是無法辨識的狀況!就是兩種傾斜狀況都要有各自獨立的處理程序的意思!
「找到字元的傾斜度」其實一直就是我能稱霸車牌辨識領域的關鍵技術!這不是甚麼「不傳」之密!只是以前真的沒有意識到這就是我跟其他車牌辨識研究者最大的差異與差距!知道了我就很願意分享,甚至這十年來我在這個辨識技術上的演算法也不斷進步,讓字元轉正的正確度越來越好,速度也越來越快!

如上就是我辨識每個字元傾斜度的示意圖!因為字元上下寬窄不一,某些字確實會歪一邊無法正確辨識傾斜度,但是絕大部分的字都可以用左右邊界的垂直方向變化分析出近似的中軸線!反正有那麼多字嘛!而且絕大多數狀況下,同一車牌的每個字傾斜度都是非常接近的,所以找個平均值或中值大家一起用就OK了!這個校正只要誤差不大都可以辨識出是甚麼字的!
我好像甚麼技術都不保密齁?確實如此!歡迎大家模仿!但是商業產品總有很多細節經驗值是需要靠點滴努力累積的!即使你完全掌握了我的核心技術做出來的品質也不容易超越我的!更何況現在根本沒有人信我這套傳統技術?我說得再清楚不藏私,我估計大多數人還是會繼續死抱著ML、DL與CNN不放!我如果開影像辨識課,事先聲明不用ML、DL與CNN,就一定沒人會報名了!因為我不AI嘛!
我只希望過些年當大家都清醒過來,我也可能已經退休甚至過世時,後人能記得或經過考古發現:在這個影像辨識的大渾沌年代,曾經有過一個我這種「眾人皆醉他獨醒」的怪咖,整天勸大家不要用ML、DL與CNN作影像辨識!我至少可以獲得一個「沒人理會的先知」的名號吧?我現在如果惦惦不講,只顧著悶頭賺錢(吃三碗公)以後就不會有人知道我有先見之明了嘛!錢不太重要的,有機會能名留青史萬古流芳才是更值得追求的好事嘛!





限會員,要發表迴響,請先登入


