
這個車牌辨識對於一般人來說還OK,但是要用影像辨識演算法辨識出來可就是一個超難的任務,因為要確認是甚麼字,終究是要把可能是字元的目標切割出來去比對字模的!字元如此模糊要如何切得盡量正確呢?先看看這張清晰車牌的色階分布圖吧!
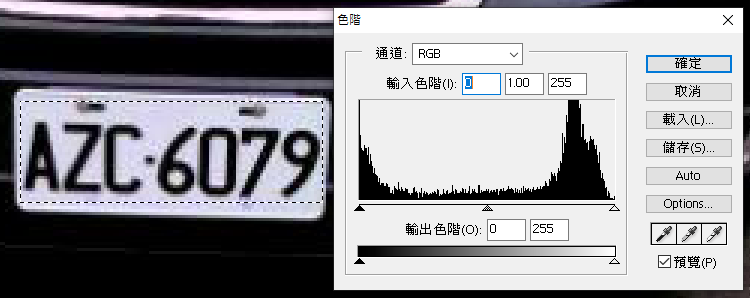
分布圖右方的高峰表示背景的白色像素們,左邊靠邊站的則是字元的黑色像素們,兩者涇渭分明,不管用甚麼粗製濫造的演算法,只要分割的門檻值落在兩峰之間的任何地方,結果都可以切出很清楚的字元黑白二值化圖。但是看看模糊車牌的分布圖吧!你看得出字元與背景像素之間的合理分界線嗎?
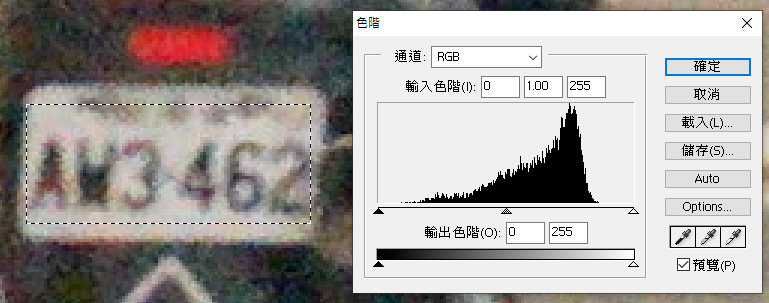
我們常常期待數學可以實現我們人都看不出來的神蹟,但事實上不會的!如上的狀況任何演算法都無法穩定的做出明確的門檻,如果用人眼以切割結果最容易識別為標準,二值化的答案如下:
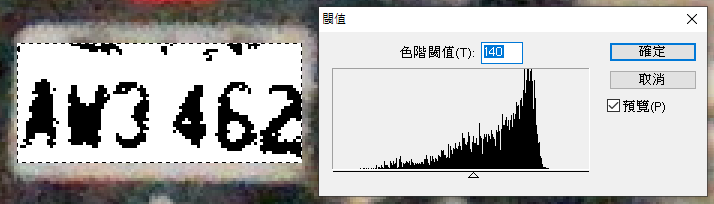
但是這個「最容易識別」是個很難量化的標準,實在沒有穩定精確的解法時,連我也必須用到機器學習的嘗試錯誤精神Learning了!我可以告訴大家我是怎麼辨識出來的!我是先從清晰車牌的雙峰理想狀況設計出一個合理的門檻計算方式,就是先算整體亮度的平均值,再稍微考慮色階分布的分散程度,微調平均值往能夠產生最大離散程度的色階移動,就是白話文說的黑白雙峰的中間位置啦!
這個算法當然在模糊到難以辨雙峰時還是會有答案的,但是結果未必是那個最容易識別的結果,很可能字元會破碎或沾連,你在色階分布圖上無法預測到哪個色階時會達到破碎與沾連的平衡點,你也不會知道車牌(或不是車牌的目標)實際上有幾個字?
所以在模糊狀況下,我的作法就是在計算「合理」的門檻結果之外,偏上偏下各取一個門檻值,看哪個猜測可以順利走到終點得到高辨識度的答案,沒有好結果就讓程式自己微調一下再試一次!那不就是機器學習的精神了嗎?是的!差別是我只在非不得已時才會使用這種猜測的方式,這是極端的例外,我會盡量不讓猜測變成主要程序,因為它們很沒效率!
這種猜測的程序我頂多做兩三次,還是不行就會放棄,因為車牌辨識大多數時候是需要講究時效的,真實世界還是有可能出現完全無法辨識的車牌,沒有客戶會接受你用十倍的辨識時間卻依舊無法辨識的!所以如果有任何明確的解法,就絕對要避免使用猜測的策略,不然程式就會慢到讓人難以接受,甚至生氣了!
我最近積極接觸學習ML的感受不只更驗證了我之前的上述想法,也知道了要盡量合理「猜測」答案的數學技巧,就是很多的機率統計概念,操作起來比我用物理推導的正常演算法更加抽象困難!所以如果有人說機器學習是可以節省研發時間,降低研發難度的技術,讓所有人都能做影像辨識?那絕對是完全外行的說法!你是可以套用很多現成的模組,但是因為很難對味,能直接獲得理想結果的機率比中樂透還低!
所以我認為理想的影像辨識研發,應該是先極盡已知的傳統演算法,精確快速的解決所有你可以掌握到的狀況,直到逼近到可以準確辨識的邊緣,像是如上的模糊車牌時,才應該考慮引進機率統計的概念!絕對不是像CNN的概念,在前處理取得大量特徵原始資料後就立即開始做機率統計!那樣做即使可以得到正確答案,嘗試錯誤造成的時間浪費很不值得!難道非要依賴超高效率的硬體(GPU)趕時間嗎?太笨了吧?有辱軟體專家的價值。




限會員,要發表迴響,請先登入


