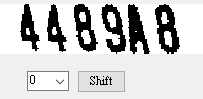
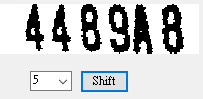
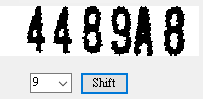
我正在寫影像辨識的書,寫到這裡必須作一種字元變形的修正,忍不住寫了一個實驗介面,讓讀者可以自己作視覺化的實驗,看看在原始影像頂部往右拉,底部不動的情況下,拉扯量不同時產生的變形修正結果。這個運算如果直接寫出程式,找到最佳拉伸量轉正影像只需要一頁的篇幅,這樣寫法就會多出好多程式碼,這些程式到最後也會被移除或註解掉,真的只是為了幫讀者思考理解用的。
我的書多半都是這樣寫的!因為我自己讀專業用書的痛苦經驗,就是作者認為不必講的過程常常就是我最難懂的痛點!尤其是影像處理,如果你給我一個精巧神奇的數學公式,幾十行程式,最後是運算結果圖,加上好多理論解說。那還不如將你認為「不重要」的處理過程圖像多貼幾張,看到視覺化的過程,任何人都可以輕鬆看懂了!
我覺得寫教材與寫論文的差異就在這裡!論文的重點是內容正確,證明你很厲害,還可以給專家驗證!寫教材的重點則是要盡量讓任何人都看得懂!至於作者是不是很厲害?用的技巧是不是最棒的?根本不重要。譬如上面的這種修正,其實我腦袋裡有七八種用過也證實可行的辦法,但是我要寫書時,並不是找出最高效率(最神奇)的那種方法,而是最容易讓讀者看懂學會的方法。
如果我堅持講最高效率,理論上「最好」的演算法,就會掉入多數專家寫教學用書的陷阱!你以為你盡力了,但是最好的方法通常也是最抽象的方法,對於初學者外行人士就是最難理解的方法!看完書之後只能讚嘆作者很神,讀者還是沒學會如何處理那些問題,而且還間接摧毀自信,不再敢大膽使用自己的常識與直覺認為可行的方法!誤以為一定要用書上寫的那些神奇演算法才能解決問題?
現在不是很多人以為,要作影像辨識一定要學CNN,OpenCV或深度學習嗎?在我的角度是完全胡說八道!這些東西我一樣都沒學過時,就可以比學過的人作出更多商業化影像辨識產品了!我最近才剛開始學那些大家說「一定要會」的東西!有沒有加分的效果?都還有待觀察!據我目前的學習進度所知,這些方法的根基也無法脫離基礎影像辨識邏輯的!不要書讀太多反而變成失根的蘭花了!
我想寫影像辨識書的動機之一,就是我從自身經驗充分體會也證實:影像辨識是一個物理問題!跟著你的物理概念,就是一些基本常識,以及數位影像的基本結構知識,你想怎麼作就試著寫程式去實現,不論姿勢好看與否?你總是可以將問題解決的!先有了堪用的方法,再來研究提升效率,努力個幾年你就有機會跟我一樣這麼商業化了!
所以我的書不會陳義過高,要將自己的影像辨識本事精銳盡出,甚至鉅細靡遺?而是希望順著讀者已經很習慣的常識直覺,引領讀者用最容易理解掌握的方式,寫出一些真的可以解決問題的程式!看得懂書的內容,敢使用學到的技術,還敢於嘗試自己的新想法,這才是我想達到的目的!
簡單說,我想寫的是有啟發性的書,不是字典,不是工具書,更不是甚麼個人的里程碑?經典著作等等。而是可以幫助你建立自信,建立一段從你的常識直覺到完成影像辨識工作門檻之間的階梯!







限會員,要發表迴響,請先登入


