
2010年台灣社會出現了白玫瑰運動,其導火線為一件高雄女童遭性侵案,卻只被法官判刑三年兩個月,造成社會輿論譁然,誕生「恐龍法官」一詞,代表民眾對司法量刑標準的疑慮。事實上,在司法實務中,科技雖讓蒐證和定罪變得相對容易,但在「衡量刑期」方面,法官仍須考量諸多因素。即使面對相似的案件,因個人經驗、法學見解或訴訟策略不同,量刑結果仍可能大相逕庭,進而引發社會對司法公正性的疑慮。因此法界有句名言:「人生有多難,量刑就有多難。」(黃榮堅教授),精準點出了量刑的複雜性,以及法官在決策過程中的困難與壓力。儘管我國憲法保障法官獨立審判,但量刑相關的法學實證研究仍然有限,難以有效回應社會對量刑公正性的期待。
也因為這個事件,司法院開始建立「量刑資訊系統」來提供過往的裁判書中的量刑資料來給法官參考。但是因為已經許久沒有人力來更新,希望透過AI來做自動標註。因此我才有機會與中正大學法律系盧映潔教授,於2020至2021年間承辦司法院「妨害性自主量刑資訊系統之AI標註與優化發展」研究計畫,並將研究成果整理後,發表於《中正大學法學集刊》第86期(2025年)。由於該期刊並無網路版,所以我以作者的身分本於「AI 公共化」的理念將之放於此處,提供更多人可以參考。全文PDF電子檔下載連結於此(超連結)。
簡而言之,本研究採用AI文字分析技術,從裁判書中擷取加重、減輕條件及量刑審酌事項,並整理出常見的量刑範圍,並且對常見的量刑考量因素做初步的統計分析。並且在此統計的基礎上開發設計一個可以更簡便使用的量刑資訊系統,為法官或法界人士對於類似案件的量刑(除妨害性自主案以外,也包含槍砲案與毒品案)可以有實證的參考基礎。我們的研究雖未進行個案預測,但希望藉此協助法官在特定範圍內進行細節調整,以平衡通案一致性與個案特殊性。即使有人認為過去的量刑結果不見得符立法者或人民的期待,也需要根據實證的統計來進行整體調整,並非僅憑少數特定人士的印象或感受來決定。當然我們這些研究都只是初步,還有許多可以強化的地方,也請各界專家不吝指教。
也在此感謝所有協助的專兼任助理與學生團隊(人工標註的法律團隊成員有李子鋐、李鳳翔、黃柏霖、楊承旻、謝旻宏;AI技術團隊的李亞倫、何捷睿、阮羿寧、林雲貂、劉弘祥、蘇晨知)。也感謝當時的司法院刑事廳彭幸鳴廳長、邱筱涵調辦事法官與文家倩調辦事法官所委託的機會,並在計畫執行過程中所給予的行政支援。
補充:目前我們自己的研究群已針對槍砲、毒品與加重詐欺罪等案件完成AI模型的初步訓練,並透過網頁平台公開展示研究成果:AI量刑預測系統(超連結)。這部分就與司法院無關,是清華大學人文社會AI應用與發展研究中心所自行研發的成果,未來將持續優化模型,並進一步探討AI科技在量刑研究中的應用潛力。但這部分並未在包括此篇文章分享中,僅此說明。
==============================
AI與量刑——以妨害性自主犯罪為例
盧映潔
國立中正大學法律系教授,德國杜賨根大學法學博士
王道維
國立清華大學物理系教授與人文社會AI應用與發展研究中心副主任,
美國馬里蘭大學大學城分校物理系博士
中文摘要
本文為司法院委託研究計畫案「妨害性自主量刑資訊系統之AI標註與優化發展」之研究計畫成果改寫而成[1]。在刑法妨害性自主罪章的21 個條文(刑法第221條第1項至第332條第2項第2款等)中,以判決數量較多的八個罪名,即刑法第221條第1項、第222條第1項、第224條、第224條之1、第225條第1項、第225條第2項、第227條第1項、第227條第3 項,將1,240篇判決書中法官呈現出量刑上的考量文字進行人工標註, 供作AI學習訓練的資料。繼而開發出一個與性侵害犯罪相關案件的AI自動標註系統,使未來不需使用人工來標註量刑審酌事項。此外,也更新了量刑資訊系統的使用者頁面,使之成為更為直覺且對使用者友善的系統。
關鍵詞: 刑法、妨害性自主、AI、量刑、量刑資訊系統
壹、研究背景
所謂「量刑」係指法官之「刑罰裁量」,亦即法官依據證據評價而認定犯罪事實及適用的罪名後,決定對該犯罪行為給予的法律效果。法官對刑罰的宣告,會歷經法定刑、處斷刑、宣告刑、定執行刑四個階段。所謂法定刑是指各個罪名條文所規定的刑罰種類及其範圍。所謂處斷刑是根據刑罰加重、減輕、免除事由,對於法定刑予以修正後所得的刑罰範圍。所謂宣告刑乃法官在法定刑或處斷刑的範圍內,對於個案所決定的具體刑罰,包括給予的刑罰種類及其刑度,也包括是否緩刑或易科罰金。所謂定執行刑則是指在裁判確定前,犯罪人成立幾個獨立的罪名法官除了分別宣告各個罪名的刑度以外,尚需依照刑法第51條各款的規定,決定被告總共應該執行的刑度。依此,在法定刑或處斷刑範圍內給予宣告刑,或在數個宣告刑的情形定其應執行刑,此屬於法官裁量權的運用,即稱為「量刑」,是故量刑是一個評價,係法官給予犯罪行為人為犯罪行為應受到何種處罰之評價[2]。
由此可見,「量刑」對刑事判決而言是非常重要的結果呈現,不但影響被告或檢察官是否提起上訴,也會深刻影響重大案件的社會觀感或媒體輿論。只是法官畢竟不是機器,不同法官對於同類案件關注的角度也 會 有 所 不 同 。 如 何 減 少 不 必 要 的 「 量 刑 歧 異 」 ( Sentencing Disparities)或如何合理有效地尋求「量刑一致性」( Consistency in Sentencing),也一直是國際上刑事司法改革上的重點之一[3]。在我國的司法改革中,司法院長也曾經表示,類似案件在不同法官判決中由於見解不一致而有量刑上的差異,自然會影響人民對司法的信賴[4]。為此, 司法院於2021年底通過《刑事案件妥適量刑法》草案,籌備設立「刑事案件量刑準則委員會」,並由該會訂定「刑事案件量刑準則」,以完善我國的量刑法制[5]。
除了法制規範的面向外,根據過往判決與量刑結果所作的實證研究,是另一種可能更為溫和間接的方式,協助法官、檢察官或刑事案件當事人/辯護人瞭解過往量刑情況並作適度的調整與對話,有助於量刑一致性的漸進推動。而這類的量刑實證研究中,近年來影響人類生活許多面向的AI科技顯然也可以扮演重要的角色,其中最常見也最多被討論的應用之一就是關於「量刑預測」,亦即利用法院判決的大量高質量語料庫來訓練機器學習模型,可以針對某些犯罪事件的內容或狀態來預測法官的量刑結果。過去幾年已經有許多不同國家進行了許多相關研究, 例如美國[6]、中國[7][8]、法國[9]、印度[10]、菲律賓[11]、泰國[12]甚至巴西[13]等等。在這些應用中,訓練用的數據與資料多是由人類法律專家標註,並使用分類變量或數值變量以方便作刑期的預測。然而,為了正確預測法院判決的結果,有些重要因素應該不能被簡單量化為數值變量或被識別為分類變量,只能用最接近法官原意的判決書文字作訓練資料。這部分近年來也因為自然語言處理的技術進步而有許多可期待的發展。然而AI 作量刑預測所可能帶來在法律與人權上的風險,近年來也有許多學者有相關的研究提出[14][15],此處就不再一一說明。
但是AI應用於司法實證研究並不僅僅只有量刑預測的方式,還可以用來作相關資料的整理與蒐集。而這個前置工作當然就是需要先對既有的判決資料作好若干整理。例如司法院為促使法院量刑得以融入人民之法律感情,自2015年起嘗試結合統計科學與量刑資訊,以大量人工、持續閱讀既往判決、標註出案件中影響量刑的各種情狀(即「量刑因子」)的方式,再以「層層篩選」原理所製成了量刑資訊系統。換言之,該量刑資訊系統,其建置概念是透過使用者輸入當前所需量刑個案的各項「量刑因子」,再與系統內的過往案件比對,找出符合這些量刑因子的過往案件之量刑結果,以作為個案的量刑參考[16]。司法院又於2018年12月21日又開始啟用「量刑趨勢建議系統」[17],除供法官審理案件之參考外,並開放檢察官、律師、學者及民眾查詢利用。然而,司法院原有的量刑資訊系統當初尚未預見目前AI的快速發展,因此過往的標註方式是脫離判決書的文字,僅以選項標註的方式來作分類,使得所標註的結果幾乎無法再藉由電腦直接從判決書取得(需要讀完全文,而判決書文字往往很長且內容結構複雜),因而較難作為未來AI或機器學習的訓練資料。
在此脈絡下,本文作者在2020年至2021年間接受司法院委託研究計畫案「妨害性自主量刑資訊系統之AI標註與優化發展」,使用2018年至2019年由地方法院做成的性侵害案件判決,共計1,240篇判決書進行人工標註。前6個月由具有法學背景的助理[18]先進行判決書人工文字標註[19],於刑法妨害性自主罪章的21個條文(刑法第221條第1項至第332條第2項第2款等)中,挑出判決數量較多的八個罪名,即刑法第221條第1項、第222條第1項、第224條、第224條之1、第225條第1項、第225 條第2項、第227條第1項、第227條第3項,共1,240篇來進行人工標註。
本文立基的上揭提及之司法院研究計畫之團隊是將判決書中法官呈現出量刑的文字敘述,依刑法第57條列舉的各項量刑審酌事項(並增加被害人的態度),分為正向、中性及負向的三種因子標註出來,供後半期AI學習訓練的資料。目前已開發出一個性侵害犯罪案件的AI自動標註系統[20],未來應可以大量減少人工標註量刑因子的需求。此外,本文立基的上揭提及之司法院研究計畫也針對過往的量刑資訊系統使用者介面進行優化,讓使用者操作上更為方便,並減少無意義的搜尋,作為現有量刑系統的更新版本[21]。目前此系統也已開放給法官、檢察官與律師使用[22],可以視為一種「可信賴的AI模型」的初步應用方式[23]。
然而,此處需要特別說明的是,人工智慧應用於司法實務遠比應用於其他領域更複雜,已在眾多文獻中探討過[24]、[25]。舉例來說,提供法律諮詢、蒐集文獻案例、分析檔案證據、草擬契約書狀等,確實有可能提高效率與品質[26][27]。其中最引人關注或許也是許多學者所擔憂的,就是應用於刑事案件的判決預測或量刑預測,而國外亦有實際案例引起大量討論[28]。但是本文立基的上揭提及之司法院研究計畫的範圍內並未涉及任何判決預測或量刑預測、亦無侵犯當事人的隱私或倫理議題,也無須修改任何人工智慧應用的規範,僅僅是單純應用自然語言處理技術,以有效率地找出判決書中的量刑適用法條與相關的量刑審酌事項。此外, 實務上即使AI標註的結果難免會有錯誤,在更新到現有的系統或資料庫前必然會由主管單位(如司法院刑事廳)的法律專家進行抽樣檢查與修改,確認最後的結果是可靠才會使用。因此本論文所研究的AI標註系統僅是協助大量減少人工標註的時間,並未因此犧牲可靠性。至於是否有其他目前未發現的問題,需要仰賴主管機關蒐集更多AI自動標註的量刑因子結果以及使用者的回饋意見後,再來評估是否需要或如何調整。此外,本文立基的上揭提及之司法院研究計畫也同時以簡明的方式呈現過往大量判決書的統計結果,讓法官或使用者能夠快速有效地掌握相關資料,進行量刑評估,始能更為透明且有依據。
貳、量刑理論、量刑規範與量刑原則
一、量刑理論
量刑是法官給予犯罪行為人應受何種刑罰之評價,但量刑之決定本質本身就是個會引起爭論的主題。本文以下簡要介紹在我國文獻上曾討論的量刑理論,諸如德國點罰理論與幅理論之量刑理論,以及美國之衝突理論、情緒控制理論以及量刑焦點關注理論等量刑理論。
點罰理論乃基於絕對應報刑思想發展而來的。採取點罰理論者認為唯一與責任相對應之刑罰,在客觀上是確實存在的,只是主觀上難以明確認識。但難以認識並不代表不存在,換言之,刑罰是一個特定的點, 以實現上級審審酌下級審法院所為之量刑是否與該點相符。並且該理論認為行為人之責任係作為刑罰裁量之基礎,不應考量預防觀點,也就是倘若刑罰裁量時考量預防觀點,會又在廣義之刑罰裁量,例如累犯等制度再次考量預防因素,將會成為對預防之雙重評價[29]。與點罰理論相對立之量刑理論即為幅理論,德國將之稱為「裁量空間理論」。德國通說見解對於量刑之基本操作方式是係採取幅理論,與點罰理論不同的是, 幅理論是基於相對應報刑思想發展而來,該理論是基於罪責評價之複雜性、人類認知能力的不充分,無法從罪責中導出確定之刑度,因此認為在決定有責之不法程度時,法官仍有一個允許之操作空間。換言之,在個案之中,與責任相當之刑罰並非是確定的量,而是一個呈現光譜式分布之量差區塊,而這個區塊中每一個點皆是適當之刑罰[30],並藉由個別預防以及一般預防的考量,在責任基礎所提供之空間內決定刑罰的量, 對於學說上則稱為「補充理論」[31],但有認為罪責基礎所提供之裁量空間不應該再考慮消極一般預防目的,蓋因立法者於決定法定刑度時已為考量,足故法官於裁量時應僅注重個別預防目的即可[32]。
衝突理論的基本觀念是,特定的群體在社會中藉由資源控制而擁有優勢的地位,而法官是代表刑事司法系統的一個組成部分,其本身就是優勢階級的成員,難免會藉由權力的運作,壓迫下級階層或是弱勢族群,例如少數民族、女人相較白人或是男人,使其受到較為嚴厲的量刑,以維護自身擁有的經濟、社會與政治利益[33]。情緒控制理論則是注重於訴訟當事人特有感情之影響,此一理論是社會學中的社會心理理論,重點放於被害人情感知覺,作為超法規變項。強調因被害者的參與,尤其是法官與被害人接觸時,量刑的歧異更加明顯。被告與被害人在一個犯罪行為後都會表現他們的情感,法官從被害人之情感顯示中獲得被害人的資訊,當被害人於犯罪後顯示悲傷時,法官可能認為被害人不應受到被侵害之對待,但若被害人顯示漠不關心、毫不在乎,則法官可能認為被害人並未受到任何不公平之對待[34]。至於量刑焦點關注理論強調,原則上適當的量刑應建立在完整的資訊基礎上,然而法官很難完整掌握資訊以及很少有時間充分調查與審酌所有量刑因子,只能將目光集中關注某些特定因素上[35]。焦點關注理論的基本觀點認為法官是依賴三個焦點關注達成量刑決定,亦即罪責、社會保障以及實踐的約束與後果。罪責此一焦點關注與應報思想聯繫,並認為法官應確保「罰當其罪」;其次,決定量刑之焦點關注則是社會保障,亦即法官藉由降低再犯的可能性來關切社會保護,同時利用有關犯罪行為的性質、前案紀錄、被告的特徵例如職業等資訊,以估算及預測被告之危險性以及未來再犯的可能性;第三個焦點關注則涉及組織與個體實踐上之約束與後果, 法官關切再犯、司法寬容對法院的名聲與自己的司法生涯之影響[36]。不過,我國有文獻提及,在我國即使不考慮非法定或稱超法規量刑因子之情形下,僅審酌我國刑法第57條所明定列舉之10款法定量刑因子,也有2,047個變項,若是再考量超法規量刑因子則情況將更為複雜。從而文獻上認為,最受法官關注的焦點因素首先為犯罪手段與犯罪所生危險或損害;其次則是犯後態度;至於行為人的品行其重要性亦受重視,犯罪行為人與被害人的關係也被認為具有較次要的意義,其餘因子則是被認為可有可無[37]。
二、我國刑法第57條的量刑相關規範
刑法第57條是我國量刑之規範依據,其謂:「科刑時應以行為人之責任為基礎,並審酌一切情狀,尤應注意下列事項,為科刑輕重之標準:一、犯罪之動機、目的。二、犯罪時所受之刺激。三、犯罪之手段。四、犯罪行為人之生活狀況。五、犯罪行為人之品行。六、犯罪行為人之智識程度。七、犯罪行為人與被害人之關係。八、犯罪行為人違反義務之程度。九、犯罪所生之危險或損害。十、犯罪後之態度。」
刑法第57條第1款行為人之犯罪動機與其希望所達成的目的,是用以判斷行為人的犯罪性及其行為罪責的主要依據。犯罪之動機例如經濟上壓力或誘因、他人的唆使、強制、來自被害人的刺激。犯罪目的例如行為人心中的情慾、仇恨、同情、貪念、義憤等。第2款犯罪時所受之刺激,行為人是否受到外界的刺激而致生犯罪,也屬於應行審酌的刑罰裁量事實,例如行為人受被害人當眾羞辱,因氣憤難忍,可作為從輕裁量刑罰的依據。第3款犯罪之的手段,不同的犯罪有不同的犯罪手段, 而相同的犯罪亦存在著不同犯罪手段。犯罪的態樣與方法等皆會影響法官對被告刑罰的裁量,若犯罪的手段使犯罪的惡害與危險性增加,會成為法官將從重量刑的考量,例如犯罪手段殘酷、施用藥劑、攜帶凶器等,造成的損害可能增大,將從重量刑。第4款所稱犯罪行為人的生活狀況,包含月收入、職業、同居人等,如行為人日常生活狀況均正常,犯罪僅偶發初犯,則有時行為人的生活狀況可作為從輕量刑事由。第5 款犯罪行為人之品行,即謂素行,一般認為包含前案紀錄及品格。前科紀錄而言,行為人先前之犯罪與本案之犯罪,刑名、罪質的異同、時間的久暫、有無關聯性,都會影響法院量刑判斷,如果刑名、罪質相同, 兼具越大且關聯性越大,其量刑從重事由的可能性越大。但前科紀錄雖然反映犯罪行為人的行為模式,不過仍要與周圍環境一併綜合判斷,而「犯罪行為人品行」,不是泛指犯罪人過去一切生活情況或任何行為人展現出來的品性,而是該生活狀況與品性已經嵌入行為人的人格特徵, 並且此一人格特徵已經形成犯罪行為的直接建構基礎。第6款犯罪行為人之智識程度,包含學歷、年齡、經歷等,一般認為犯罪行為人的智識程度與社會上是否期待其不為犯罪有正向關聯性,故對於具有高教育水準與高社經地位的犯罪行為人,以其遵守法律規定的期待可能性較高, 一旦違法,可責難的程度較高,於量刑方面會考量加重。第7款犯罪行為人與被害人之關係,犯罪行為人與被害人的身分關係如越密切,行為人若基於與己身特殊情形的親友為不法侵害,通常會認為惡性重大而從重量刑。第8款犯罪行為人違反義務之程度,違反義務的情節、程度各不一,違反義務程度重者,從重量刑。第9款犯罪行為人所生之危險或損害,犯罪所生的後果,包含對被害人身體健康之傷害,用以酌量犯罪行為對被害人身體健康之傷害程度的裁量。犯罪發生的危險程度、直接或間接之物質上或精神上損害的大小皆影響刑罰輕重的裁量。第10款犯罪後之態度,行為人於犯罪後的態度亦為法官量刑的依據,通常法官對於行為人行為後不知悔改、惡意狡辯多會從重量刑;相反的,若行為人行為後,坦承犯行、表現後悔、向被害人道歉、回復損害或賠償被害人所受損失多會從輕量刑[38]。
三、量刑原則及近期發展
(一) 罪刑相當原則
刑法第57條各款所列舉的是法官量刑時的參考,但不代表法官只能考慮這些審酌事項,而法官量刑時應遵照「罪刑相當原則」。我國過去大法官解釋中多次論及「罪刑相當原則」,諸如司法院釋字第544號、第551 號、第602 號、第630 號、第646 號、第662 號、第679 號、第669 號、第775號、第777號解釋以及新近的112年憲判字第13號判決。112年憲判字第13號判決稱「對於因犯罪行為而施以剝奪人身自由之刑罰制裁,除限制人民身體之自由外,更將同時影響人民其他基本權利之實現,是其法定自由刑之刑度高低,應與行為所生之危害、行為人責任之輕重相稱,始符合憲法罪刑相當原則,而與憲法第23 條比例原則無違」。雖然上揭釋字與憲法判決是在於處理法定刑是否過重的問題,但是亦展現出法官在科予刑罰時應審酌行為所生之危害、行為人責任之輕重等等一切事項,也就是說法官量出來的刑度必需相應於行為人應負擔的罪責。因此,法官在量刑時應審酌的事項當然不限於刑法第57條各款所列舉的事由。
(二) 平等原則
「平等原則之要求是『對相同之條件事實,始得為相同之處理』, 倘條件事實有別,則應本乎正義理念,分別予以適度之處理,禁止恣意為之」[39]。我國最高法院早有提出「量刑應符合平等原則」的觀點[40]。但過去採取此種見解的判決,引用平等原則說明的對象幾乎都是「同案中的共同被告」之量刑問題[41]。不過,較近期有臺灣高等法院105年交上易字第117號判決要旨謂「平等原則之誡命既是『對相同之條件事實,始得為相同之處理,倘條件事實有別,則應本乎正義理念,分別予以適度之處理,禁止恣意為之』,準此,其他同類案件之量刑,因量刑係以行為人之責任為基礎, 而刑事罪責復具個別性,相類似案件之量刑分布查詢結果,自因個案情節不同而不能逕執為量刑之準據。然相類似案件之量刑分布卻足可供為量刑時用以檢驗個案裁量結果是否確有畸重、畸輕;如有顯著乖離,法院則應盡其說理義務,並排除裁量結果係因非理性之主觀因素所致之量刑歧異,以此濟量刑裁量之審查標準抽象、審查密度偏低之窮,並昭折服」。也就是相類案件之量刑不應有顯著差別。
而司法院於2018年8月7日所函頒的「刑事案件量刑及定執行刑參考要點」以及司法院邀請專家學者召開會議針對各種常見的犯罪中的量刑原則作出相關的建議而製作的「刑事案件量刑審酌事項參考手冊」,還有上揭提及的「量刑資訊系統」、「量刑趨勢建議系統」,雖然為避免觸及「審判獨立」的核心,強調只有「建議」性質,但是其目的也是希望能達成量刑的一致性。此外,司法院近年來也積極推動量刑法治化, 也包括設立「刑事案件量刑委員會」,並希望制訂具有拘束力的量刑準則[42]。
(三) 量刑程序中被告訴訟權的保障
在刑事訴訟程序中,量刑程序其實與審判程序同屬重要階段,而我國司法院曾在釋字第775號解釋理由書表示:「目前刑事訴訟法,⋯⋯對於科刑資料應如何進行調查及就科刑部分獨立進行辯論均付闕如。⋯⋯ 相關機關應依本解釋意旨儘速修法,以符憲法保障人權之意旨」。另憲法法庭在112年憲判字第14號判決有更明確表示,因犯罪追訴、論罪科刑與被告人身自由等重要權利密切相關,刑事訴訟程序自應受憲法正當法律程序原則更嚴格之要求,故憲法判決主要從憲法保障被告訴訟權及保障人身自由權之基本權論點,認為論罪科(量)刑涉及訴訟權及人身自由權之保障,應受到憲法正當法律程序原則之要求。依此,在量刑程序中應有被告訴訟權的保障。然而在量刑程序中應落實被告哪些訴訟權的保障,有文獻以美國聯邦最高法院判決在量刑程序建構之基本程序權保障的發展[43],指出被告應享有辯護權之保障、量刑資訊之受告知權、提出證據之權利、對質詰問權之行使、請求證據開示權利、一般量刑因子證明責任至優勢證據之程度[44]以及加重刑罰要件證明責任須至超越合理懷疑證明程度[45]。而文獻見解認為[46],在我國由於辯護權之保障、提出證據之權利、對質詰問權之行使等權利在量刑程序尚無疑義,我國可參考美國法制之處是量刑資訊告知及量刑加重告知,亦即倘若法院完全未告知被告量刑資訊(或量刑加重資訊、偏離量刑資訊)時,係違反被告憲法正當法律程序之基本權。對於無論是加重、減輕及其他科刑資料,或者包括量刑情狀鑑定或量刑前調查報告,法院若要採取此等證據資料,而打算加重(偏離)以往的量刑趨勢或行情,為使被告事先受告知而有事前準備及辯論量刑資料(證據)之機會,應給予更詳盡之受告知權之保障,此是屬於量刑正當法律程序原則之內涵。
四、小結
本文立基的上揭提及之司法院研究計畫係以量化法實證研究為主要的研究方式,以應用於機器學習的研究結果來與學理上闡述的量刑理論以及量刑規範來進行對話。其中量刑事實部分主要是以我國刑法第57條規定的量刑因子之事實文字敘述來進行標註。這些資訊經過整理後分析出司法實務的經驗,可供關注量刑議題者將量刑理論、量刑規範與實務經驗進行對照比較,如此一來才能完整我國的量刑研究,從而發現在司法審判的實務面向是否存在著與量刑理論上有不一致的地方,減少不必要的司法資源耗費,亦可將理論、實證與實務三者作更緊密的結合。
本文立基的上揭提及之司法院研究計畫是對判決書之量刑審酌事項的文字敘述進行標註以及加重減輕法條的選項標註(詳見下述),從而發展出對現行司法院量刑系統之優化,能夠使審判者、檢察官及律師更容易在相同的量刑審酌事項以及與其對應的刑度上達成共識。這也有助於平等原則在量刑上的運用,亦有助於法院對被告進行量刑資訊的告知,讓被告方也更能夠針對量刑事項進行有效防禦。故本文立基的研究計畫所得成果對於提升司法人權應能發揮一定的作用。
參、妨害性自主犯罪量刑審酌事項之人工標註原則
一、量刑審酌事項之人工標註的考量
在本文立基的上揭提及之司法院研究計畫進行人工標註的過程中, 發現幾乎沒有一篇判決會列出所有刑法第57條列舉的量刑審酌事項,亦發現某些量刑審酌事項顯然是妨害性自主犯罪最常被法官考量到的。因此,在進行正式標註前,團隊先試著標註幾十篇判決來得到初步的統計結果,並將這些統計結果用以設計一個更為符合判決書實際內容並可以有效減少不必要人力或時間浪費的標註清單。
基此,在量刑審酌事項方面,依出現比例的高低,本文立基的上揭提及之司法院研究計畫將標註分為以下幾項:1.「犯罪後態度」(第10 款)。2.「犯罪手段與所生之損害」(第3款與第9款)。3.「被害人之態度」(新增)。4.「犯罪行為人之品行」(第5款)。5.「其他審酌事項」。至於「犯罪的動機與目的」(第1 款)、「犯罪時所受之刺激」(第2款)、「犯罪人之生活狀況」(第4款)、「犯罪人之智識程度」(第6款)、「犯罪行為人與被害人之關係」(第7款)、「犯罪人違反義務之程度」(第8款)等等,由於法官提到的次數非常少,或是提到時幾乎都只是用中性語氣的帶過,難以看出對量刑的影響,所以不特別標出,就全部歸於「其他審酌事項」的類別。
此外,在標註的過程中,本文立基的上揭提及之司法院研究計畫發現「犯罪手段」與「犯罪與所生之危險與損害」兩者在妨害性自主犯罪的判決中常常是連在一起描述,很難加以區分。因此團隊將這兩者合在一起標註,如此更正確的反映出法官實際表達的內容。最後,雖然起初也有標註性交的時間與次數,但是後來發現各法官認定是否對被告不利的標準差異頗大,而且幾乎也都同時包含在「犯罪手段與所生之損害」相關的文字描述中,故後來決定無須再另外標註。
二、人工標註原則與範例
本文立基的上揭提及之司法院研究計畫所使用的判決是由司法院所提供,是2018年至2019年由地方法院做成的性侵害案件判決總計1,409 篇判決書,由其中挑選判決書篇數較多的8個法條,共計1,240篇判決書的人工標註。裁判書人工標註的方法是,由五位法律研究所研究生助理分別進行法定加重或減輕相關法條選項及量刑審酌事項的文字標註。量刑審酌事項的文字標註原則是將判決書中法官作為量刑審酌事項的文字敘述,分為有利、不利及中性三個類別進行標註。標註歷程分為標註練習、正式標註及二次確認之檢查,以完成歷經多次審閱後的標註資料。關於如何判讀法官審酌事項的文字是有利或不利於被告,以下簡單介紹在人工標註上的作法:
在不利於被告的部分,研究團隊發現大多是法官在判決書中明確地使用負面的字詞,可以清楚地認知到法官在裁判書此段文字對於被告的量刑是不利的,則會標註不利,例如「動機可議」、「殊不可取」。例如「犯罪行為人之品行」與「犯罪行為人犯罪後之態度」這兩個事項, 前者法院經常提及行為人具有前科,而且法院通常會將行為人具有前科在犯罪行為人之品行這個事項上呈現不利的敘述,所以有前科部分會標示不利;後者是只要行為人否認犯罪,法院通常在犯罪後態度這個因子上會有不利的敘述,所以行為人否認犯罪部分會標示不利。
在量刑審酌事項有利的文字部分,研究團隊發現只有法官在裁判書明確使用正面的字詞,可以清楚地認知到法官在裁判書此段文字對於被告的量刑是有利的,才會標註為對被告有利,例如「被告應有悔意」、「態度尚佳」等等。但是有兩個例外的是在行為人與被害人和解與行為人犯罪後之態度的判斷上,其一是只要有行為人與被害人和解,便在被害人的態度部分標註有利,其二是只要行為人坦承犯罪,則在犯罪後之態度的部分標示有利。
在中性或不明確的部分,則是法官在裁判書只提示相關的文字,但是卻無相對應的評價,又無法從一般觀念中認定,例如「逞一時性慾」,這幾乎是所有性犯罪所共有的敘述,其實已經屬於犯罪的罪名中所包含的基本概念,不應該再於量刑中作重複評價。又例如強制性交罪中提及「違反他人性自主權」與「違反他人意願」,亦屬此類。因此, 只要是成立犯罪就必然會伴隨的特性,如果法院沒有明示其判斷為何需要量刑更加嚴重,即便一般觀念會認為這是對被告不利,仍應該將此量刑審酌事項標註為「對被告中性或不明確」。
除對被告有利、對被告不利與對被告中性或不明確以上三種評價類型,團隊也有標註「看似有利卻轉折不利」與「看似不利但轉折有利」的句子。因為法官撰寫判決書時常出現類似的轉折語氣。但是後來在作AI標註訓練的時候,這類轉折文字由於數量明顯相對較少,因而分別併入「對被告不利」以及「對被告有利」的標註結果中。
肆、妨害性自主犯罪量刑審酌事項之統計分析
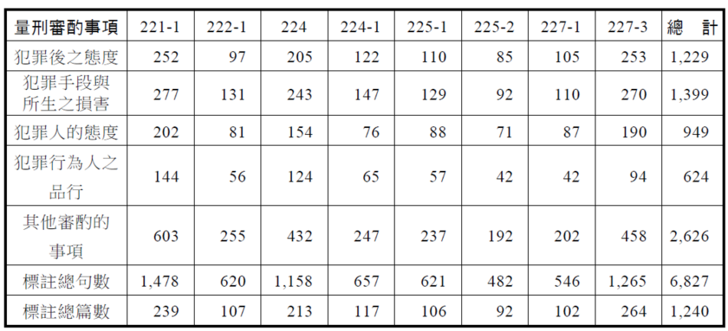
以下分別針對人工標註結果,最常出現也最可能影響量刑的幾個審酌事項作相關的統計說明。在目前經過人工標註的1,240篇妨害性自主案件的判決書中,可以看到不同的罪名法條的標註數目差距不小,主要是因為該案的判決書篇數有很大的差距。但整體來說,平均每篇可以得到約6827/1240=5.5句的標註結果。
表一:各罪名的案件數目與所提到的量刑審酌事項的人工標註數目。222-1代表刑法第221條第1項,其餘類推。224之1代表刑法第224條之1。
一、犯罪後態度
此部分由於判決理由涉及了犯罪人是否向被害人道歉、回復損害、賠償被害人所受損失,對應的是刑法第57條第10款「犯罪後之態度」。在犯罪後之態度部分最主要觀察到的是被告有無與被害人達成和解或調解,若有和解或調解則判決中多為有利敘述,例如「已與被害人達成和解並賠償完畢」等,若無和解或調解則多為不利敘述,例如:「迄未與被害人達成和解或調解」、「事後未賠償告訴人之損失」。不過就和解或調解結果上而言,和解或調解成立與否並不一定影響量刑的有利與否,例如「被告有意與被害人和解,惟因被害人請求高達25萬元美金之賠償金額,而無法獲得被害人之諒解」、「被告雖未能與被害人達成和解,然並非無與其和解之意,僅雙方認知條件有所差異」等。
其次,被告有無道歉或取得被害人的原諒也是此部分的觀察重點之一,如被告有道歉或取得被害人的原諒,則判決中多為有利敘述,例如「取得被害人之諒解」,如未道歉或取得原諒,則會多為不利敘述,例如「被害人甲女於本院審理中仍表示不願意原諒被告」、「被害人表示不願原諒被告」、「尚未求得被害人之原諒」。
再者,「犯罪後之態度」會考量自行為人為犯罪行為後至審理結束這段期間之犯罪後之態度。如果被告始終不坦承犯罪則屬態度不良,例如「斟酌被告犯後否認犯罪,毫無悔意之犯後態度」;若被告是始終坦承犯罪則屬態度良好,例如「念及被告於警詢、偵查及本院審理時均坦認客觀犯行,非無悔意之犯罪後態度」。不過,也有被告也態度反覆,先態度良好而後態度不良,或是先態度不良而後態度良好,裁判書中尤其會指出被告態度反覆的狀況,例如「被告於警詢時猶飾詞辯稱A女主動與其發生性行為而否認對A女實行強制力,又於偵查之初辯稱其不知A女年紀,嗣後始向檢察官坦承為犯行,暨於本院審理階段仍坦承犯行」。此外,在犯罪後之態度部分,本文立基的上揭提及之司法院研究計畫中發現亦有涉及被害人或其家屬直接針對量刑提出意見,例如「告訴代理人並請求從重量刑」、「被害人家屬於本院審理時業表示:被告道歉毫無誠意,請法院依法判決等語」、「被害人甲女亦當庭表示:希望判處被告重一點,被告已非初犯,這樣的人不值得被原諒,一點都沒有要反省」等。關於標註結果中,此量刑審酌事項對被告有利或不利的比例,可參考圖一的統計。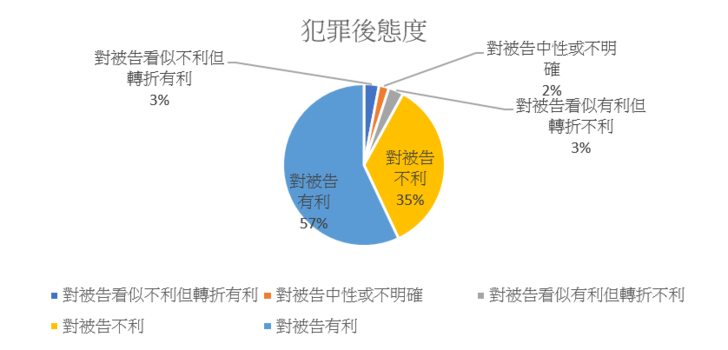
二、犯罪手段與犯罪所生之損害
此部分對應到刑法第57條第3款「犯罪之手段」及第9款「犯罪所生之危險或損害」,係以法官對於被告行為的手段內容以及對被害人的生理或心理損害等描述進行標註。此部分的描述,大多是對被告不利者,且大多係針對對被害人所造成的影響進行描述,例如「戕害被害人之身心發展,且對於被害人日後人際關係與男女間正常交往,所生之障礙與可能造成之創傷,均不無重大影響」、「其所為對被害人造成身心恐懼及陰影,妨害社會治安甚鉅,實殊無可取」、「不僅侵害被害人之性自主決定權,並戕害被害人身心發展甚鉅,所為自應予嚴厲譴責非難」、「竟漠視他人之性自主決定權及身體控制權,違反被害人之意願,對被害人為強制性交行為,其所為不僅造成被害人心理上難以磨滅之陰影,且危害被害人之身心健全發展,恐對被害人日後之人際關係及人格成長造成影響,殊值譴責」。然而也有少部分的對被告的有利敘述,例如「被告係一時衝動,犯罪情節、手段尚非殘暴」、「係因一時衝動失慮而犯案,未使用工具,亦未造成被害人衣物破損或身體受傷」、「被告行為時係憑藉身材上之優勢壓制被害人, 並未施以暴力或使用兇器迫使被害人就範」、「其違反告訴人意願之手段亦非激烈暴力行為」等,可見係以行為人犯罪手段的暴力程度作為有利或不利的判斷。亦有看似不利但轉折為有利,例如「與被害人為性交行為,對被害人之身心健康與未來人格發展造成不良影響,然考量被告年紀亦輕,因認與被害人為男女朋友而發生性行為」等。關於標註結果中,此量刑審酌事項對被告有利或不利的比例,可參考圖二的統計。
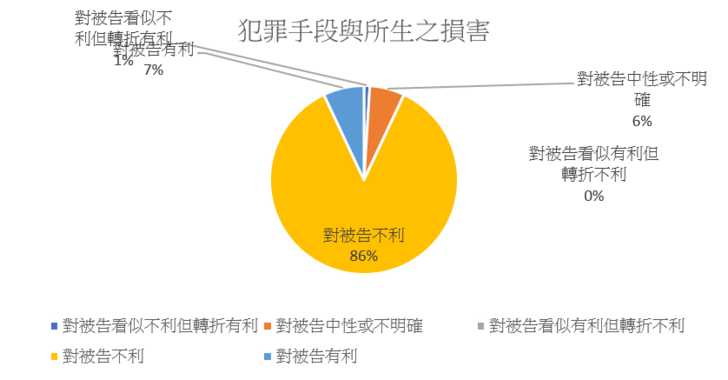
圖二:犯罪手段與所生之損害之量刑評價統計
三、被害人之態度
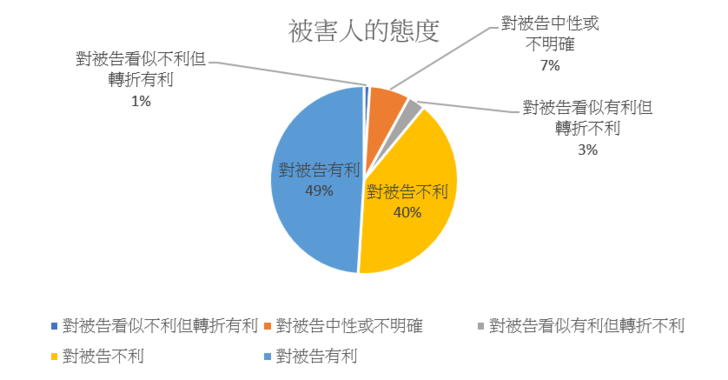
此部分由於內容涉及了是否向被害人道歉、回復損害、賠償被害人所受損失,部分也涉及了被害人的具體意見,無從歸納於刑法第57條各款,例如「被害人家屬於本院審理時業表示:被告道歉毫無誠意,請法院依法判決等語」、「被害人甲女於本院審理中仍表示不願意原諒被告」、「被害人甲女亦當庭表示:希望判處被告重一點,被告已非初犯,這樣的人不值得被原諒,一點都沒有要反省」等,此乃本文立基的上揭提及之司法院研究計畫中的初步發現,法官在具體個案中之量刑, 未必均參照刑法第57條所示之各款事由進行。
此部分主要獲得之觀察,首先係被告有無與被害人達成和解或調解,若有則判決中多為有利敘述,例如「已與被害人達成和解並賠償完畢」等,若無則多為不利敘述,例如:「迄未與被害人達成和解或調解」、「事後未賠償告訴人之損失」,不過就結果上而言,和解或調解與否並不一定影響量刑的有利與否,例如:「被告有意與被害人和解, 惟因被害人請求高達25萬元美金之賠償金額,而無法獲得被害人之諒解」、「被告雖未能與被害人達成和解,然並非無與其和解之意,僅雙方認知條件有所差異」等;再者,被告有無取得被害人的原諒也是此部分的觀察要點之一,如被告取得被害人的原諒,則判決中多為有利敘述,例如「取得被害人之諒解」,如未取得原諒,則會多為不利敘述, 例如「被害人表示不願原諒被告」、「尚未求得被害人之原諒」。此外,亦有被害人或其家屬直接針對量刑提出意見,例如「告訴代理人並請求從重量刑」、「參酌被害人原請求對被告從重量刑,因雙方和解而請求依法處理等情」、「被害人於本院審理期日所陳述之量刑意見」等。關於標註結果中,此量刑審酌事項對被告有利或不利的比例,可參考圖三的統計。
四、犯罪行為人之品行
刑法第57條第5款「犯罪行為人之品行」,發現判決理由中主要係以法官有無參酌被告前科紀錄表的相關敘述。如果被告無前科,則多為有利敘述,例如「被告前未曾受有任何刑之宣告,有臺灣高等法院被告前案紀錄表可稽」、「被告於本案前並無犯罪經法院判處罪刑之前科, 此有台灣高等法院被告前案紀錄表1份,素行良好」、「被告前無任何前科紀錄」,如果被告有前科,則多為不利敘述,例如「被告前已因妨害性自主案件,經判刑確定,竟再為本案犯行」、「被告於緩刑期間內,猶不知恪遵法律規範、反省己過、謹言慎行」、「審酌被告犯前述前科紀錄,素行不佳,經執行完畢,仍不知悔改再犯本案性侵害案件, 足徵被告法治觀念薄弱,視法律如無物」、「被告前於103至105年間有傷害、竊盜、寄藏子彈、肇事逃逸、妨害自由、妨害公務等多項前科, 可見對於社會秩序及他人之身體、財產法益均乏尊重,各經法院予以論罪科刑甚或執行完畢後,仍未衷心悛悔」等。由此可觀察到,在妨害性自主的案件中,法官以前科來對於犯罪行為人的品行良否的判斷,並不是以先前犯過相同類型之妨害性自主案件為判斷,而是有無刑事犯罪的前科,亦即只要有前科,法院通常會將其以不利的因子為判斷。不過, 也有判決對於犯罪行為人的品行的描述無法確認為有利或不利,例如「參酌被告之素行」,則會列為中性因子。關於標註結果中,此量刑審酌事項對被告有利或不利的比例,可參考圖四的統計。
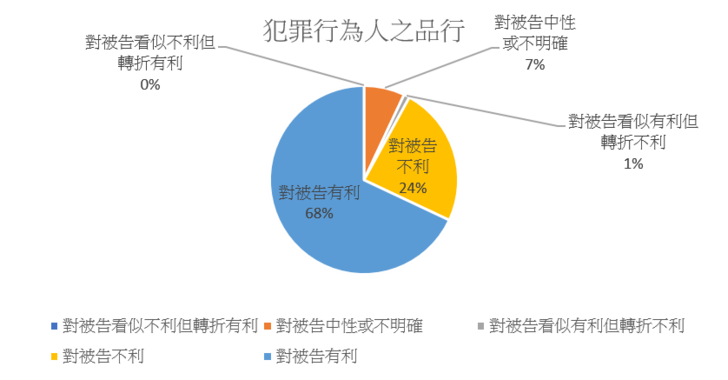
圖四:犯罪行為人之品行的量刑評價統計
五、其他審酌事項
在其他(不分類)的部分,若無法歸類在上述各該因子中的敘述, 則會歸類在此,惟種類繁多,諸如被告的學歷、年齡、家庭成員、經濟收入、婚姻狀況等等,在這個因子種類繁雜,這部分判決書中有法院沒有表示其判斷的結論,為中性論述;也有法院為有利或不利的論述。其他(不分類)的部分,其與刑法第57條各款對應的有第4款、第5 款、第6款、第8款,也有無法與第57條各款對應者。與第57條第4款「犯罪行為人之生活狀況」對應的有「行為人應扶養的對象」、「行為人之經濟收入」、「行為人之婚姻狀況」,例如「復考量被告於本院審理中自陳其智識程度國中肄業、在便當店工作、月收入約新臺幣3萬2,000多元、未婚、無小孩」;與第57條第5款「犯罪行為人之品行」對應的有「行為人過往之善行」,例如「兼衡被告提出之從事公益活動照片,其亦有善良之一面等一切情狀」;與第57條第6款「犯罪行為人之智識程度」對應的有「行為人之學歷」、「行為人之年齡」、「行為人的智能或精神狀況」,例如「兼衡被告自述為高職畢業之智識程度」、「且案發時被告年僅18歲餘,年輕識淺,思慮未臻成熟」、「被告的年紀將近70歲,行事上不該莽撞,更該有分寸」、「被告有發展遲緩及學習障礙之情形,經鑑定結果認總智商落於非常低之範圍,對一般事實性知識、所處社會環境理解及判斷力稍差,無法在特定情境中選擇最有效的方法來處理特定問題,影響其遵守社會規範標準的能力」、「衡以被告於案發時衝動控制之能力確有下降,有中醫大附醫精神鑑定報告在卷可憑」;與第57條第8款「犯罪行為人違反義務之程度」則有「犯罪行為人違反義務之程度:被告於審理時陳稱被害人於案發當天詢問可否當他乾爹等語……,被告竟罔顧被害人對其之信任,而為本件猥褻犯行」等。
以下列舉若干無法與第57條各款對應的判決書內容:
(一)行為人再犯的可能,例如「被告行為時係未滿18歲之少年,自制力低,人生經驗不足,易受外界引誘、影響,其歸責可能性也低,具有相當大的教育可塑性,學習能力強,如予以適當之再教育,重歸正途之機會甚大」、「且離婚後離開家中不再有接近被害人之機會」。
(二)行為人矯治成功復歸的機會,例如「念其年紀尚輕,仍有可為,倘令被告入監服刑,恐未收教化之效,先受與社會隔絕之害」。
(三)行為人與被害人於犯後的相處狀況,例如「被告已與告訴人結婚」、「被告自105年1月間起即與被害人開始同居,並於106年6月15日產下一子,雙方於被害人年滿16歲之後即已結婚,被害人復於107年6月間又生了第二個孩子,目前被害人及二名幼兒均需待被告早日服刑完畢返家團聚,並由被告負起扶養之責等」、「更令A女因此產下一子,為一般社會大眾及法律無法容忍舉凡令A女懷孕、產女之痛苦過程至女嬰未來之撫養照顧責任,完全置身事外,根本毫無關心可言」。
(四)檢察官的意見,例如「檢察官則以起訴書表示請求本院從輕量刑,以勵自新」。
(五)行為人家庭的功能完整性與否,例如:「被告家庭功能支持系統完整,為從輕考量事由」。
關於標註結果中,此類量刑審酌事項對被告有利或不利的比例,可參考圖五的統計。
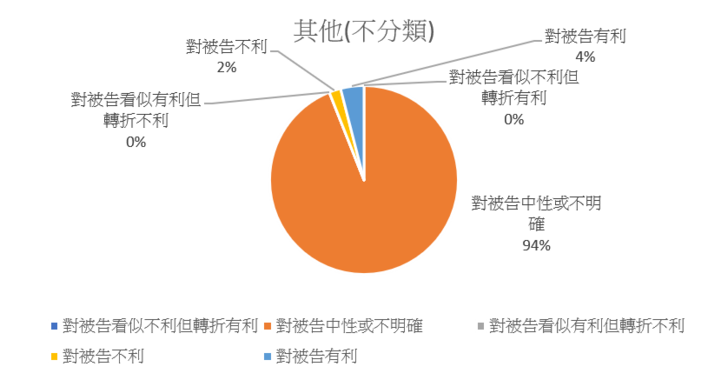
圖五:其他審酌事項之量刑評價統計
伍、量刑審酌事項的AI語意分類與自動標註
在人工標註完1,240篇左右的判決書以及得到超過6,000句以上的標註文字後,接下來的目標就是希望能夠利用人工智慧中自然語言處理(Natural Language Processing, NLP)的技術,將人工標註的結果作為機器學習的訓練資料,發展AI自動標註的模型[47]。這個功能的重點比較在於如何用電腦取代大量的標註人力,使未來的判決書可以不需要經過專家的標註而直接從判決書中讀取與量刑相關的訊息,並且放入前述的量刑資訊系統介面來供法官、檢察官、律師或民眾參考[48]。本計畫使用此技術來標註量刑審酌事項,因為判決書中對審酌事項的文字表述方式更為多元,涉及語意分析而無法如加重減輕法條搜尋那樣先從法條的關鍵字入手。但是好處是多集中於某個段落,不需要全文搜尋。由於AI技術牽涉到許多資訊工程專業領域的細節,無法在此詳述,以下會僅就相關的基礎架構來略為說明。
一、自動標註流程設計
本文立基的研究的自動標註流程可約略以圖六來呈現。包括基本的訓練與測試流程,最後才是實際的應用。在訓練與測試的過程中,首先整理妨害性自主案件所標註的1,240篇判決書中,依照刑法第57條各款所列的量刑審酌事項文字。這些句子都事先經過人工標註分類,屬於「犯罪後之態度」、「犯罪手段與所生之損害」、「被害人的態度」、「犯罪行為人之品行」或「其他審酌事項」五類當中的某一類。並且每一句話都有「對被告有利」、「對被告不利」或「中性或不明確」三種評價。所以會先將這些文字先轉換成256維度的向量來代表,並且透過類神經網路(Artificial Neural Network)來進行分類模型的訓練。
本文立基的上揭提及之司法院研究計畫所設計的AI分類模型共有兩種,一種是類型判斷,另一種是評價判斷[49]。在類型判斷中,我們針對以上所述常見的五種量刑審酌事項分別設計一個模型,來分辨「是否屬於犯罪後之態度」、「是否屬於犯罪手段與所生之損害」、「是否屬於被害人的態度」、「是否屬於犯罪行為人之品行」以及「是否屬於其他審酌事項」,總共五種二分類的模型。也就是說,同一個句子會先被送到五個審酌事項的分類器,而這五個類型的判斷彼此是獨立的。這樣做的好處是,如果某個句子同時可以歸屬於兩類以上的因子,亦可以被適當的標註而非互相排擠,只能有一個結果呈現。此外,人工標註的時候,也是希望所標註的文字有一定的長度好讓AI可以有效判斷,因此有可能會混雜兩種以上的概念。但是由於各個審酌事項是獨立判斷,所以這部分就能如實呈現其結果。
在類型判斷以後,如果某句子被分類到以上五類中的任何一類,就會再送到評價判斷的模型,確認屬於對被告有利/不利/中性或不明確。但是如果一個輸入的句子並不屬於任何一種類型(也就是非標註句,本計畫有另外截取來作對照組),就不會再作評價判斷。最後,再根據每一個量刑審酌事項所得到文句分類結果,再作綜合性判斷屬於這篇判決書的評價。絕大多數情形下,法官對於某個審酌事項可能會提到一句或兩句,但是評價都是有利或不利於被告。只有極少數的判決書會出現法官對同一個因子同時有對被告不利與有利的文字。此時就會改標記成對被告中性或不明確。
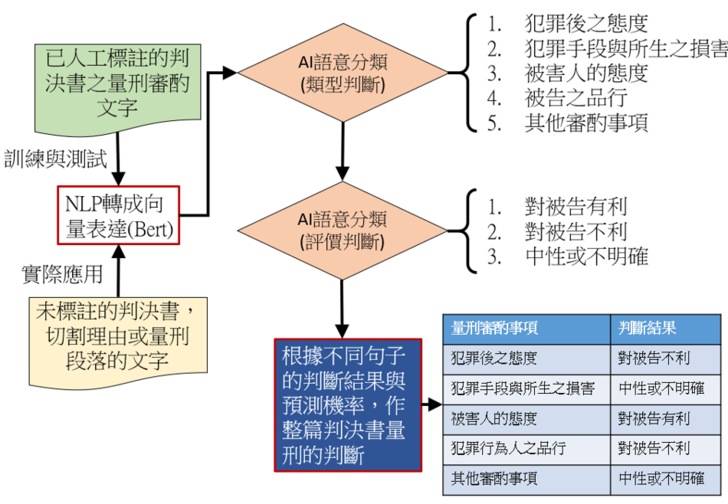
圖六:上揭計畫所設計的AI自動標註的流程圖。首先是使用人工標註的資料進行模型訓練,分類量刑因子的類型與意向,得到相當的準確度以後,再應用於未標註的判決書
二、AI語意分類模型簡介
在將文字輸入機器學習之前,需要先作資料清理,也就是將一些數字(如日期、法條或數量等)作用代號先作處理,免得電腦因此當作文字訊息來計算關聯性,因而誤判為某種語意。一般來說接下來是需要先透過斷詞的處理並且將不同的詞作編號,再用自然語言處理的方式來將每個詞與前後詞之間的關係轉化成高維度的向量來表達,也就是所謂的詞向量(word vector)[50]。
但是AI技術部分已經不再需要透過前述的斷詞工作來進行,而是利用深度學習模型來建立一個能夠準確判斷法律條文適用性以及量刑審酌因子的文字分類模型。過往用來處理這樣工作的深度學習模型包括遞迴神經 網路 ( Recurrent Neural Network, RNN )[51]、卷積神經網路(Convolutional Neural Network, CNN)[52]與最近很流行的基於轉換器的生成式預訓練模型(Generative Pre-trained Transformer, GPT)[53]等。
經過仔細的比較與過慮,本文立基的上揭提及之司法院研究計畫的團隊選擇以Google AI團隊開發的基於Transformer架構的預訓練語言模型 BERT(Bidirectional Encoder Representations from Transformers)[54]作我們自然語言處理的前端預訓練程式[55],因其雙向深度的自我注意力機制(self-attention model)在考慮每個單詞和上下文關係時可以超越傳統的RNN和CNN模型。這是因為BERT的Transformer架構是可以根據訓練的結果自動計算每個字的權重(Embedding Weight),讓模型預測的結果更為可靠。此外BERT的Transformer是一種Encoder架構,而GPT的Transformer是Decodor架構,所以前者雖然不如後者適合文字生成,卻可以比較準確的解決分類問題[56]。這不僅增強了實際作業時的平行計算能力,後來再搭配判決書中已經經由人工標註所得到的相關文字來提升文句的分類效果(也就是遷移式訓練,Transfer Learning),有助於AI 學習不同判決書中獨特的文字單元之間的長距離依賴關係。最後,再將按照這樣方式訓練而成的向量送入類神經網路來直接作二分類或三分類的模型,判斷是否屬於某種類型或是否對被告有利。
事實上,在我國的司法判決中,BERT也曾被廣泛應用在其他目標的研究上[57][58],取得一定顯著的成功,因此所利用BERT模型來作的自動標註工作亦應有相當的可靠性。然而,需要考慮的是,BERT的官方中文預訓練參數在處理每個句子時,最多僅有128個字。但是研究團隊的標註結果發現,所得到的量刑審酌事項的文字經由前述適當的分類後,都沒有超過128字的句子需要被截斷,因此BERT這部分的限制並不會影響本次的研究成果。
除了以上被人工分類出來的「已標註句子」外,另外從「爰以……」或「爰審酌……」開頭的段落中,以電腦自動抓取了3,000句的「非標註句」來放入那些「其他審酌事項」中的「中性或不確定」類型,一起加入訓練與測試的資料集中。這樣做的目的是因為,為了要作好AI自動標註,模型不但是要能從「已標註」的句子中分類出某個類型,也要能從那些其他不需要標註的句子中區別開來。這樣才能算是比較合適的模型訓練。本文立基的上揭提及之司法院研究計畫使用以上資料集中的80%作訓練資料,20%作測試資料,作後續的模型訓練。其餘的類型也如此比照。
如果某句子確定屬於某一類,再進行評價的分類,判斷是屬於對被告有利、不利或中性的論述。在這個評價判斷的模型中,就「其他審酌事項」,將所有的對被告有利、對被告不利與對被告中性或不確定的句子都拿來訓練,這樣才能蒐集夠多的句數來訓練好模型。這當然是假定(也應符合事實)法官在撰寫關於某類量刑審酌事項的常見用詞與評價對被告是否有利不利的用詞,是互相獨立的。前者多於該量刑審酌事項的專有名詞有關(例如自白、悔悟、兇殘、前科等等),但是後者多是與描述的方式有關(例如良好、尚可、竟不惜、仍不知等等)。
三、AI語意分類測試結果
以下分別用表二來表示(a)「是否屬於犯罪後之態度」、(b)「是否屬於犯罪手段與所生之損害」、(c)「是否屬於被害人的態度」、(d)「是否屬於被告之品行」以及(e)「是否屬於其他審酌事項」這五個AI語意分類模型的測試結果。此處我們使用機器學習常用的混淆矩陣(confusion matrix)的方式來呈現:兩列的數值代表本身是否是某類句子,而兩欄分別代表所預測的結果。這樣呈現的好處是,可以同時知道有多少句子從人工來看是符合某類量刑審酌事項,但卻被AI誤判,而又有多少句子是不符合該類事項卻被AI認為符合。因此對角線數值相對於全部總數的比例越大,就代表越正確。
表二:AI語意分類模型(類型判斷)對於不同量刑審酌事項的預測結果
|
(a)犯罪後之態度正確度=98.52% |
AI模型預測的結果 | ||
|
是 |
否 | ||
|
人工標註的結果 |
是 |
240 |
18 |
|
否 |
11 |
1,696 | |
|
準確率(Precision) |
95.60% |
98.90% | |
|
召回率(Recall) |
93.00% |
99.40% | |
|
F1-分數(F1-score) |
94.30% |
99.20% | |
|
(b)犯罪手段與所生之損害正確度=97.61% |
AI模型預測的結果 | ||
|
是 |
否 | ||
|
人工標註的結果 |
是 |
265 |
24 |
|
否 |
23 |
1,653 | |
|
準確率(Precision) |
92.00% |
98.60% | |
|
召回率(Recall) |
91.70% |
98.60% | |
|
F1-分數(F1-score) |
91.99% |
98.60% | |
|
(c)被害人的態度正確度=97.87% |
AI模型預測的結果 | ||
|
是 |
否 | ||
|
人工標註的結果 |
是 |
176 |
21 |
|
否 |
21 |
1,747 | |
|
準確率(Precision) |
89.30% |
98.80% | |
|
召回率(Recall) |
89.30% |
98.80% | |
|
F1-分數(F1-score) |
89.30% |
98.80% | |
|
(d)犯罪行為人之品行正確度=99.44% |
AI模型預測的結果 | ||
|
是 |
否 | ||
|
人工標註的結果 |
是 |
108 |
6 |
|
否 |
5 |
1,846 | |
|
準確率(Precision) |
95.60% |
97.70% | |
|
召回率(Recall) |
94.70% |
99.70% | |
|
F1-分數(F1-score) |
95.20% |
99.70% | |
|
(e)其他審酌事項正確度=97.30% |
AI模型預測的結果 | ||
|
是 |
否 | ||
|
人工標註的結果 |
是 |
533 |
34 |
|
否 |
19 |
1,379 | |
|
準確率(Precision) |
96.60% |
97.60% | |
|
召回率(Recall) |
94.00% |
98.60% | |
|
F1-分數(F1-score) |
95.30% |
98.10% | |
由此可以看得出, 這五個量刑審酌事項都有相當高的正確度(> 97%),不管是從預測的準確率或是否完整的找到相關的句子的能力上,代表模型能夠順利的分辨這些類型的因子(不管評價如何)。值得注意的是,「其他審酌事項」也有高達97.30%的正確度,即使其中明顯包含許多不同的類型,如動機與目的、家庭情狀、智識程度、與被害人關係等等因素,而這些因素表達的詞彙或方式當然也有許多不同的類型。這部分之所以能有此水準的原因在於加入了更多非標註的句子(也不是其他審酌事項,因而可以區分出一般的句子還是屬於審酌事項的句子),幫助AI可以用更好的方式來分辨不同類型的文字特色。可見這個類型判斷的AI語意分類模型算是相當成功的。
表三顯示另一個AI語意分類模型(評價判斷)的預測結果。在判斷一個句子對於被告是有利、不利還是中性或不明確的三分類上,這個模型仍有非常好的表現,整體的正確度超過93%,而個別類型的準確率或召回率等都有至少90%以上,顯示相當一致的結果。當然,因為這個三分類資料中包含各種不同類型的量刑審酌事項,在分類上的確就比較麻煩一些而稍微拉低了準確度。若要改善這個結果,理論上只需要針對不同的因子再訓練這樣的評價分類即可,但是那樣對於某些比較數量較缺乏的類型,例如前四個量刑審酌事項都很少中性或不明確,而其他審酌事項中絕大多數是中性或不明確,對被告有利或不利的評價反而較少, 這些也都會影響分開訓練模型的準確度。所以區分類型判斷與評價判斷的兩種語意分類模型,應該是比較有效的策略來應用在實際的判決書資料中。
表三:AI語意分類模型(評價判斷)的預測結果
|
評價判斷 正確度=93.38% |
AI模型預測的結果 | |||
|
對被告不利 |
對被告有利 |
中性或不明確 | ||
|
人工標註的結果 |
對被告不利 |
487 |
4 |
34 |
|
對被告有利 |
4 |
330 |
29 | |
|
中性或不明確 |
34 |
25 |
1,018 | |
|
評價判斷 正確度=93.38% |
AI模型預測的結果 | ||
|
對被告不利 |
對被告有利 |
中性或不明確 | |
|
準確率(Precision) |
92.80% |
91.90% |
94.20% |
|
召回率(Recall) |
92.80% |
90.90% |
94.50% |
|
F1-分數(F1-score) |
92.80% |
91.40% |
94.30% |
四、實際應用於未標註的判決書
以上所設計或訓練的AI語意分類模型,將使用在尚未由人工標註的判決書,摘取量刑審酌事項的相關文字並加以判斷,如表四。可以發現的是,判斷正確的結果(「AI判斷欄位」為黑色字)算是還不錯,多半都能正確的抓到該段文字中對於量刑審酌事項的正確判斷。此外,由於本文立基的上揭提及之司法院研究計畫加入非標註句的訓練,因此也不會隨意將本段中的每一句話都進行標註,因而保持相當的類似人工標註的結果。
但是也可以發現,仍然有些句子可能沒有正確的判斷(「AI判斷欄位」為粗體字),主要是受到法官對於個案描述的影響,並非訓練時所能完全排除的文字,因而被部分錯誤的判斷。又或是因為用語有轉折或目前的斷句未完整所影響。這些都是目前法院判決書沒有被適當結構化的原因所致(也就是法官的理由沒有一一對應的欄位,全部混在一起)。雖不能排除以後有更好的演算法來改善,但短時間內並非容易改進的地方。真正釜底抽薪的方式是讓法官在判決書撰寫的過程就進行結構化的設計,才能讓每一條理由被正確的判斷,對未來的量刑也才會有更好的參考。舉例來說,可以在量刑的段落以選項的方式勾選出刑法第57條中的各款或其他常見審酌事項,必要時才補充其他文字。這樣既可節省法官寫判決書的時間、減少不必要的疏漏,也能讓當事人閱讀或未來的量刑研究都可以更為清晰明白。
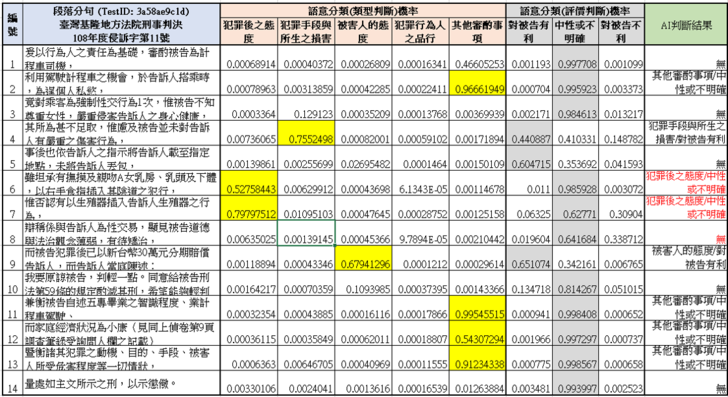
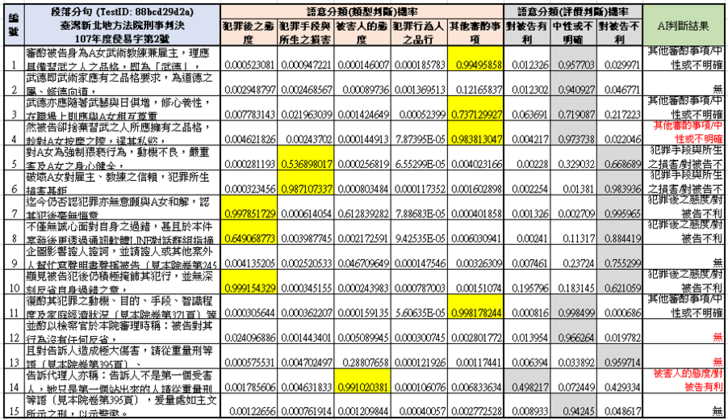
表四:AI自動標註對未標註的判決書之量刑審酌事項預測機率與判斷結果,以隨機選擇的兩篇判決書為例。其中深灰底色的格子代表類型判斷中,機率被預測大於0.5的類型。淺灰底色的格子代表評價分類中機率相對較大的選項。最右邊的欄位代表AI自動標註的結果,其中「無」代表該句子在類型判斷中無法歸類於五類中任何一類,所以就不會作任何標註。黑色與粗體色字分別代表AI自動標註正確或有錯誤的地方(經由人工事後判斷)
對於量刑資訊系統而言,這個自動標註的重點在於為「全篇判決」決定某些量刑審酌事項的結果,而非裡面每一句的判斷都需要準確。舉例來說,表四的下圖,臺灣新北地方法院107年度侵易字第2號判決,其第4句「然被告卻捨棄習武之人所應擁有之品格,趁對A女按摩之際, 逞其私慾」被預測為「其他審酌事項/中性或不明確」。雖然這比較合適的分類於「犯罪手段與所生之損害/對被告不利」,但其實第5、6兩句已經有這類的結果,所以若以整篇判決來看,其實並無缺少這個量刑審酌事項。而本來所歸類的「其他審酌事項/中性或不明確」雖然無法避免,但是因為第1、3、11句也都是有同樣的分類(且正確)的結果, 所以從整篇的標註來看,也並未因為此句的分類問題而讓整篇在這個量刑因子上有錯誤。而第12、13句判斷的錯誤(預測為並非需要標註的句子),雖然應該屬於「犯罪後之態度/對被告不利」,但這部分也已經為第7、8、11句所涵蓋。因此其實也並未造成整篇標註結果的錯誤。
因此,可以發現的是,即便有些許的標註句可能有預測錯誤,但是對於整篇判決標註的影響應該比預期的還要小,這也是此種複雜的判決書難以避免的部分(甚至人工閱讀也可能有誤)。所以重點是這些標註也可以藉由本系統的標註修改平台進行人工修改,讓這些錯誤有機會修正,後來更可以反過來成為未來AI自動標註時的訓練資料。
陸、系統前端的頁面操作說明
一、系統設計的目標
當初本文立基的上揭提及之司法院研究計畫的目標之一,是開發一個可以更新或取代現有量刑資訊系統的電腦系統。需要強調的是,上揭研究所作的「量刑資訊系統」並非「量刑預測系統」[59]。後者為要到達高準確度,會需要盡可能增加更多的參數或選項,但前者是為了搜尋到最相關的判決書,應該是盡可能用較少的參數比較合適。所以這個系統一定要能減少使用者的時間並且帶來有效的資訊供量刑參考。為了要讓使用者覺得好用,本系統使用者介面需要減少選取的選項以節省使用時間,常常能得到可參考的結果,不會因為查不到判決書而造成困擾,結果呈現清楚而知道適當的量刑區間,並可直接查詢判決的細節[60]。
因此本文立基的上揭提及之司法院研究計畫先運用統計的結果,瞭解哪些法條或因子是最常被提到,再作為設計系統的參考,讓使用者可以直覺式的使用,很快可以得到量刑統計的結果。但如果有其他疑問也可以進一步的搜索瞭解細節。
二、量刑選項的頁面安排
本文立基的上揭提及之司法院研究計畫已在量刑資訊系統上呈現以下八個較為常見的罪名:(一)「刑法第221條第1項」(強制性交罪)、(二)「刑法第222條第1項」(加重強制性交罪)、(三)「刑法第224條」(強制猥褻罪)、(四)「刑法第224條之一」(加重強制猥褻罪)、(五)「刑法第225條第1項」(趁機性交罪)、(六)「刑法第225條第2項」(趁機猥褻罪)、(七)「刑法第227條第1項」(對未滿14歲性交罪)、(八)「刑法第227條第3項」(對滿14歲但未滿16歲性交罪)。其他的罪名,所得到的判決書數目相當的少,因而暫時不放置於本系統的網頁, 可以留待後來蒐集更多判決書後再加入。以下將以「刑法第221條第1 項」(強制性交罪)逐步解說本系統在妨害性自主相關案件中的設計。這裡所呈現的標註資料是以法律團隊所進行的人工標註為基礎,時間範圍是民國107年1月到民國108年12月間總數共239篇。為方便說明起見,使用以下系統網頁的截圖來說明。
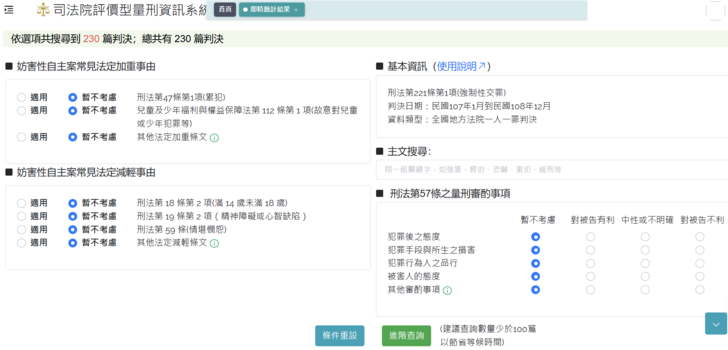
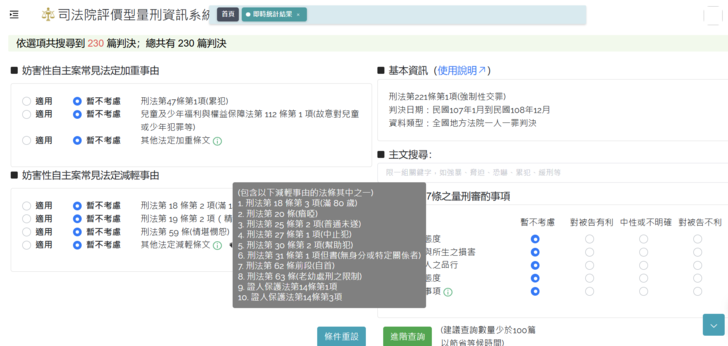
圖七:(上圖)量刑資訊系統測試版,進入「刑法第221條第1項」的首頁頁面選項的配置。(下圖)當游標接近「其他較少出現的法定加重/減輕條文」時,會列出本系統有搜尋過的法條與罪名,供使用的法官參考
從圖七可以看到,進入妨害性自主類型的頁面後首先會看到右邊有關於這個頁面的法條與罪名,並且列出此資訊所蒐集的日期範圍,讓使用者可以明確知道所搜尋的內容是否是在其預定的範圍。在此處也設計了一個搜尋框,可以針對判決書的主文來進行搜尋。例如,如果法官希望搜尋到針對「恐嚇」而強制性交的案件,只需要輸入「恐嚇」兩個字就能找到關於持有的案件作為搜尋的目標之一。這樣不但可以分別出「強暴」、「脅迫」、「恐嚇」等不同的罪名,也可以搜尋其他在主文中可能有助於法官進一步區別的文字,例如「累犯」或「緩刑」等等。 畫面的左半邊列出加重減輕的法條,並提供使用的法官點選的圓框,右半邊是部分量刑審酌事項的選項(暫不考慮/對被告有利/中性或不確定/對被告不利)。這部分的加重減輕法條資訊來源是由電腦的關鍵字搜尋的結果,而量刑審酌事項目前是使用人工標註的結果來呈現。當游標接近「其他較少出現的法定加重/減輕條文」時,會列出本系統有搜尋過的法條與罪名,供使用的法官參考(見圖七下圖)。但是對於不同的罪名或適用的法條,並非每一個明白列出的法定加重或減輕的法條都有平均的被引用。若有需要,使用者可以透過第二層的進階查詢很快地找到進一步的資訊。
初始的設定(在沒有改變勾選條件下)是將選項都放在「暫不考慮」以顯示所有的相關判決案件之結果,也就是會顯示出「全部案件的刑期分布」。刑期的曲線代表此類案件整體的結果,並不會因為選項而變化,可作為後來點選其他選項時的對照參考值。長條圖代表每個區間的判決書數量,則是會因為不同的選項而有所調整。這個預設的目的是為了讓法官不作任何選擇前就可以大致瞭解本罪名在過去判決結果的分布情形,在案件數目比較少的情形下,甚至不需要點選其他的資訊就可能可以判斷適合的刑期。如勾選加重法條「刑法第59條」(情堪憫恕),長條圖就會出現變化,是根據所選取的項目所作的即時統計(如圖八)。這代表因為有減輕的法條,所找到的案件量變少,但是很明顯多是分布於刑期較低的地方。若游標靠近其中一個長條圖(例如最高的那一支, 24 至30 個月),就會顯示該範圍的判決書數目。
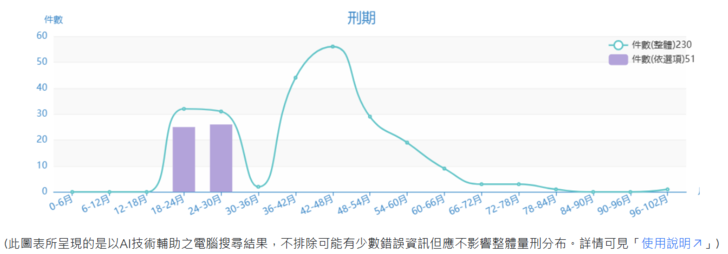
圖八:「刑法第221條第1項」在有刑法第59條的減輕事由作為篩選條件下,所得到的刑期分布
在右方的量刑審酌事項中,目前只有列出五個,分別是「犯罪後之態度」、「犯罪手段與所生之損害」、「被害人的態度」、「犯罪行為人之品行」與「其他審酌事項」,而每個有四種評價選項,包括「暫不考慮/對被告不利/中性或不明確/對被告有利」。之所以選擇前四個因子而將其他的因子歸於「其他審酌事項」的原因是,根據人工標註的結果,前四者有被法官列為有利或不利於被告的評價,在句子數目的比例上都超過全體的90%,但「其他審酌事項」(包括刑法第57條中其他各款,例如動機與目的等)中卻不足20%,有非常明顯的差異。
以之前所點選「刑法第59條」的減輕事由為例,如果再加選「犯罪行為人之品行」中「中性或不確定」的選項,那麼就只會變成只有16 篇,分布如圖九。
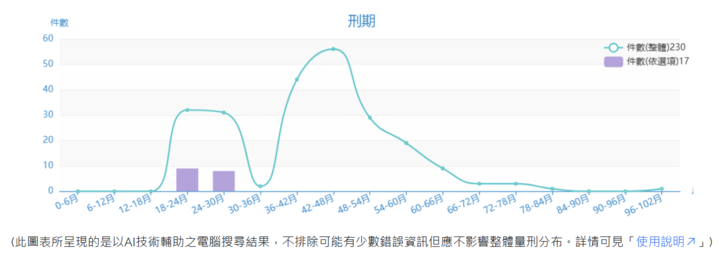
圖九:「刑法第221條第1項」在有刑法第59條的減輕事由並量刑因子「犯罪行為人之品行>中性或不確定」作為篩選條件下,所得到的刑期分布
從圖九的結果可以看出,在這兩個條件下,過去的判決中,多數是判在18到30個月之間,幾乎沒有其他刑期的案件。也就是說,法官使用到這裡(僅點選兩個選項)就可以按照其心證,考慮其案件的特性(即便還沒有選相關的量刑審酌事項)而決定是否比18到30個月更重一些, 還是更輕一些。因此,本系統的設計是法官不必辛苦點完所有的法條或因子才會得到案件的統計結果,而那時又常常會發現因為設定的條件增加,最後能得到的判決反而減少!後者的情形正是目前的量刑資訊系統的問題所在。至於目前的判決為何會有些判決是偏低,那就可以點進所對應的個別判決來瞭解。這部分以下會再說明。當然,此時也可以藉由搜尋主文中的「脅迫」、「累犯」或「緩刑」等文字而進一步限制所要尋找的判決書類型。
這也是研究團隊為何一開始就強調,以使用者(法官)的方便性來說,並不需要列出所有的加重減輕法條或所有的量刑因子來勾選,那只會浪費使用者的時間卻又很可能得不到任何有意義結果。這是量刑資訊系統本質上與量刑預測系統不同之處,後者理論上都可以提供一個預測結果,不管所輸入的資料彼此是多麼矛盾或不一致。但反過來說,若這些輸入資料與真實的案例相差頗大時,這樣的預測又如何能有可靠性值得參考?這就是一個兩難的問題。但至少量刑資訊系統在使用上,都是呈現出有具體判決結果的案件數目與相關統計,可以藉由補充更多的案件而達到參考的價值。若真的案件數太少,也是真實狀況的反應,比較不會誤導使用者。這是計畫的團隊在設計之初所作的重要規劃方向。
三、判決書進階查詢的頁面設計
除了快速得到量化的統計結果作為量刑區間的判斷參考以外,法官也可能想要進一步瞭解是哪些判決書作出這樣的決定,或查詢其他類似或相關的案件,確認是否有特別的原因或理由。因此本系統的設計還可以往下選入第二層,查詢相關的判決書。進入的方式是點選刑期的長條圖,或是點選「進階查詢相關的判決書」就會進入到下層頁面,呈現相關的判決書資訊。
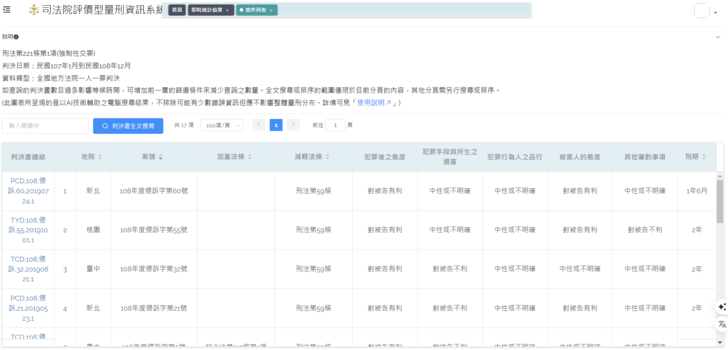 圖十:「刑法第221條第1項」進入第二層之類的案件列表。將每個符合第一層篩選條件的判決表列出來並附上相關的加重減輕法條、量刑因子以及刑期等。最後附上該判決書的連結,可以進入第三層閱讀判決書的內容
圖十:「刑法第221條第1項」進入第二層之類的案件列表。將每個符合第一層篩選條件的判決表列出來並附上相關的加重減輕法條、量刑因子以及刑期等。最後附上該判決書的連結,可以進入第三層閱讀判決書的內容
當點選入這個第二層的頁面時,本文立基的上揭提及之司法院研究計畫設計一個如圖十的表格,可以完整的呈現出每篇符合第一層篩選條件的判決,包括判決書的全文連結、地院名稱、案號、所使用的加重減輕法條、量刑審酌事項以及最後的刑期等。為了比較有效率的呈現這些符合條件的判決書,此處會以分頁的方式呈現,而使用者可選擇每頁呈現10、20、30、50篇的判決,最多可到500篇,以減少分頁的情形。如頁面的文字說明,若要一頁顯示越多的判決,呈現或搜尋的速度就會變慢。這是考慮到未來可能會有更多的判決書,所以預先安排的設計免得一次顯示太多判決書而造成使用上的時間拖延與其他的不便。
此外還針對判決書的地院名稱、案號、加重減輕法條,以及刑期設計排序的功能,而初始的順序即是以刑期來排序。這樣法官可以馬上評估他主要想要查詢的資料而進入排序,更快的找到所進一步研究的判決。但是由於分頁的關係,目前的排序也就只能在該頁面中作排序,而非對所有搜尋到的判決書排序。因此如果第一層的條件太少,所得到的判決書超過50篇,進入第二層以後就可能需要超過一頁的方式來呈現。在這樣的條件下,如果要使用排序的功能,就需要針對每一頁的內容來分別排序。所以這也是用來限制第一層的搜尋可以適度的限制範圍以減少第二層進階搜尋的篇數,這是一個魚與熊掌的問題,需要平衡搜尋的速度、排序的分頁、以及第一層初篩的條件等等因素,需要使用者更加熟悉後,瞭解所需要找到的判決書性質而調整。
再者,也在這裡增加關鍵字搜尋功能,可以針對當下的頁面上所顯示的判決書作全文搜尋。這樣的功能可以協助法官在使用的時候,除了列表中的欄位資訊以外,可以再作進一步的全文搜尋而找出所需要的資訊。但是如同排序的問題,如果第一層的條件設的太寬,以至於第二層有太多的判決書列出,那麼就會需要作分頁分次的搜尋。所以前面設計的篩選判決書的條件也會影響到後來進一步使用的方便性。因此前一層的篩檢條件越少,後面需要釐清的時間可能就比較多。但如果前面篩檢的條件越清楚,所得到的判決書數量減少也就方便或加速第二層的進階搜尋。所設計的系統希望可以由法官自行按照其需求來用不同的使用方式拿捏調整,保持使用的彈性與效率。
最後,如果使用法官需要更仔細閱讀判決書的內容來確定若干判決的理由或細節,就可以從第二層的判決書連結點入,會看到如圖十的顯示結果。在這樣的頁面中,使用者除了判決書全文外,也會看到關於這篇判決的標註結果(但不包括文字標註)。如果法官在閱讀判決書的內容期間,對於右方的標註結果有疑義或發現有錯誤,就可以透過一個回報的按鍵來回傳相關資訊給後台的管理者,方便後來作進一步的修改或調整。
柒、結語
本文立基的上揭提及的司法院研究計畫已經完成以下幾個重要的目標,包括:一、完成超過1,200篇關於妨害性自主案件的判決書人工標註。二、完成對妨害性自主案件量刑因子的敘述統計分析。三、開發「前後文輔助的關鍵字模糊搜尋」技術。四、建置判決書標註資料庫(包含人工與電腦搜尋的結果)。五、統計法官所常引用的加重減輕法條並量刑審酌事項作為系統選單的參考。六、開發方便使用的網頁介面並呈現統計搜尋的結果。七、開發方便整體呈現判決書搜尋的網頁供法官進一步參考。八、開發標註編輯平台作為未來判決書標註資料的修改。九、開發AI文字語意分類模型,驗證效果。十、建置量刑因子AI自動標註系統,對新判決書的量刑審酌事項進行標註。
本文立基的上揭提及之司法院研究計畫結合量刑原則、判決書實務研究、人工專業標註、量化統計分析、AI語意分類模型建置、系統頁面設計等等不同領域的技術,希望能為我國司法量刑的量化研究與實務運用提供一個參考的基礎。有文獻提到[61],在刑事程序中運用AI來進行各種預測或判斷,會有其客觀的效率,在一定程度內可以降低決定者在個案中可能帶有的偏見,但是在司法相關程序中建置AI系統時,可能沒有完整評估其是否考量了不當因素,以致於AI系統運作的結果會受到偏見的影響。要減少AI系統存在的偏見而獲得社會大眾的信賴,重要的是與公眾的溝通,以及透明性或者說要使外界得以檢視[62],並且有事後的評估與監督。對此,本文認為需要說明的是,一方面本文立基的研究計畫所開發建置的並非量刑的預測系統,建置的「量刑資訊系統」也不是作為法官量刑時的判斷而只是參考之用,應無損害法官獨立審判的精神; 另方面本文將研究計畫成果形成文章加以發表,作者用意也在於對所開發建置的「量刑因子AI自動標註系統」以及「量刑資訊系統」是採用哪些樣本資料、是如何進行人工標註、採取什麼訓練程式以及訓練與測試的過程等等事項加以公開,使外界得知系統是如何運作,以達到透明性的要求。
至於與公眾的溝通以及事後的評估與監督方面,本文立基的上揭提及之司法院研究計畫所開發建置的「量刑資訊系統」,目前司法院僅開放給法官、檢察官與律師使用,尚未對社會一般大眾公開。本文作者期待未來司法院能在運用「量刑因子AI自動標註系統」標註了更多判決的量刑因子而更新的「量刑資訊系統」,並且能夠進一步開放給社會一般大眾使用,俾以就量刑的實然面與社會大眾溝通,建立更好的法治教育基礎。此外,本文立基的上揭提及之司法院研究計畫「量刑資訊系統」具有使用者回饋的功能,可讓目前的使用者(法官、檢察官與律師)回報人工標註或AI自動標註的錯誤之處,或提供改善的意見,這已經具有專家的事後監督功能。倘若司法院能夠蒐集使用者的回報資料並加以整理分析,再對「量刑資訊系統」進行調整,應該可以增加該量刑系統的正確性。
附註
[1] 司法院「妨害性自主量刑資訊系統之AI標註與優化發展」之研究計畫,計畫主持人為本文第一作者,共同主持人為本文第二作者,執行期間為民國109年12 月25日至民國110年12月24月。本文部分內容曾於2023年11月27日在「第27屆全國科技法律研討會」進行口頭發表,而後再調整、添補內容始形成本文。於研討會之口頭發表以及投稿期刊發表,皆有獲得司法院之同意,但本篇文章內容不代表司法院立埸。而「妨害性自主量刑資訊系統之AI標註與優化發展」研究計畫執行之初,已有獲得中正大學人類研究倫理中心之倫理審查通過,同意研究證明書編號:CCUREC110041501。特此說明。
[2] 吳景芳,量刑基準之研究,頁1-2,國立臺灣大學法律研究所碩士論文,1982 年6月。
[3] 吳景芳,美國之聯邦量刑改革法,刑事政策與犯罪研究論文集(三),頁25,司法官學院犯罪防治資料庫網站提供下載電子檔,https://www.cprc.moj.gov.tw/ media/8235/462711352150.pdf?mediaDL=true(最後瀏覽日:2023年3月28日),原載於:刑事政策與犯罪研究論文集(三),頁19-41,2000年11月。
[4]【大法庭上路】避免司法像月亮 司法院長:不再初一十五不一樣,鏡週刊,2019 年7 月4 日報導, 請見https://www.mirrormedia.mg/story/20190704inv009/(最後瀏覽日:2023年3月28日)。
[5] 參見司法改革進度追蹤資訊平台: https://judicialreform.gov.tw/Resolutions/Form/?fn=66&sn=1&oid=6(最後瀏覽日:2023年3月28日)。
[6] Daniel Martin Katz, Michael J. Bommarito & Josh Blackman, A General Approach for Predicting the Behavior of the Supreme Court of the United States, 12(4) PLOS ONE e0174698 (2017).
[7] Bingfeng Luo, Yansong Feng, Jianbo Xu, Xiang Zhang & Dongyan Zhao, Learning to predict charges for criminal cases with legal basis, Cite as: arXiv:1707.09168: https://arxiv.org/abs/1707.09168 (July 28, 2017, last visited: Dec. 24, 2023).
[8] Haoxi Zhong, Zhipeng Guo, Cunchao Tu, Chaojun Xiao, Zhiyuan Liu & Maosong Sun, Legal Judgment Prediction via Topological Learning, in PROCEEDINGS OF THE2018 CONFERENCE ON EMPIRICAL METHODS IN NATURAL LANGUAGE PROCESSING3540-49 (2018).
[9] Octavia-Maria Sulea, Marcos Zampieri, Mihaela Vela & Josef Van Genabith, Predicting the law area and decisions of French supreme court cases, Cite as: arXiv:1708.01681: https://arxiv.org/abs/1708.01681 (Aug. 4, 2017, last visited: Dec. 24, 2023) .
[10] Vijit Malik, Rishabh Sanjay, Shubham Kumar Nigam, Kripa Ghosh, Shouvik Kumar Guha, Arnab Bhattacharya & Ashutosh Modi, ILDC for CJPE: Indian legal document scorpus for court judgment prediction and explanation, Cite as: arXiv:2105.13562v2: https://arxiv.org/abs/2105.13562 (May. 31, 2021, last visited: Dec. 24, 2023).
[11] Michael Benedict L. Virtucio, Jeffrey A. Aborot, John Kevin C. Abonita, Roxanne S. Avinante, Rother Jay B. Copino, Michelle P. Neverida, Vanesa O. Osiana, Elmer C. Peramo, Joanna G. Syjuco & Glenn, Brian A. Tan, Predicting Decisions of the Philippine Supreme Court Using Natural Language Processing and Machine Learning, in 2018 IEEE 42ND ANNUAL COMPUTER SOFTWARE AND APPLICATIONS CONFERENCE (COMPSAC), vol. 2, at 130-35 (2018).
[12] Kankawin Kowsrihawat, Peerapon Vateekul & Prachya Boonkwan, Predicting Judicial Decisions of Criminal Cases from Thai Supreme Court Using Bi- Directional GRU with Attention Mechanism, in 2018 5TH ASIAN CONFERENCE ON DEFENSE TECHNOLOGY (ACDT) 50-55 (2018).
[13] André Lage-Freitas, Héctor Allende-Cid, Orivald Santanao & Lívia Oliveira-Lage, Predicting Brazilian Court Decisions, 8 PEERJ COMPUTER SCIENCE e904 (2022).
[14] 陳鋕雄、楊哲銘、李崇僖,人工智慧與相關法律議題,元照,頁1-61,2019年9月。
[15] 龍建宇、莊弘鈺,人工智慧於司法實務之可能運用與挑戰,國立中正大學法學集刊,第62期,頁43以下,2019年1月。
[16] 刑事量刑專區,參見司法院網站網頁: https://www.judicial.gov.tw/tw/cp-83-57186-1ef46-1.html(最後瀏覽日:2023年8月24日)。
[17] 量刑趨勢建議系統, 參見司法院網站網頁: https://sen.judicial.gov.tw/pub_platform/sugg/index.html(最後瀏覽日:2023年8月24日)。
[18] 司法院「妨害性自主量刑資訊系統之AI標註與優化發展」研究計畫,進行判決書人工標註的法律團隊成員有李子鋐、李鳳翔、黃柏霖、楊承旻、謝旻宏,本文「肆、妨害性自主犯罪量刑審酌事項之統計分析」的內容為人工標註的成果分析,對於法律團隊就執行計畫的付出與本文形成的貢獻,本文作者特此感謝。
[19] 關於標註平台的介紹與使用說明,參見王道維,文字標註系統導論線上課程,網址: https://nthuhssai.site.nthu.edu.tw/p/404-1535-238010.php(最後瀏覽日:
2023年8月24日)。
[20] 司法院「妨害性自主量刑資訊系統之AI標註與優化發展」研究計畫,進行技術開發的團隊成員有李亞倫、何捷睿、阮羿寧、林雲貂、劉弘祥、蘇晨知,本文「伍、量刑審酌事項的AI語意分類與自動標註」的部分有技術開發團隊的貢獻。對於技術團隊就執行計畫的付出與本文形成的貢獻,本文作者特此感謝。
[21] 文家倩,量刑與AI的交會──淺談司法院量刑資訊系統的革新,當代法律,第
10期,頁6-12,2022年10月。
[22] 由於此系統目前僅開放給法官、檢察官與律師使用,尚未對一般大眾公開。相關資訊可參考司法院新聞稿:「因應國民法官新制,司法院啟用AI量刑資訊系統──具備二種模式、擁有四大優點」,2023年2月6日。司法院新聞稿網址: https://www.judicial.gov.tw/tw/cp-1887-806741-d6471-1.html(最後瀏覽日:2023 年8月24日)。
[23] 王道維、邱筱涵,當ChatGPT來敲法官的門──淺談AI應用於司法審判的原則與方式,當代法律,第18期,頁6-28,2023年6月。
[24] 如同陳鋕雄、楊哲銘、李崇僖,同註14。
[25] 如同龍建宇、莊弘鈺,同註15。
[26] 蕭奕弘,人工智慧之新發展與在司法實務上之應用,檢察新論,第25期,頁3- 27,2019年2月。
[27] 王紀軒,人工智慧於司法實務的應用,月旦法學雜誌,第293期,頁93-114,2019年9月。
[28] 如美國著名的Loomis v. Wisconsin案,可參考Harvard Law Review, Vol. 130,
1530 (March 2017) ,網址: https://harvardlawreview.org/print/vol-130/state-v- loomis/(最後瀏覽日:2023年12月24日)。
[29] 吳佶諭,從刑罰目的觀論刑罰裁量,頁77,文化大學法律學系碩士論文,2008 年6月。
[30] 梁家昊,量刑理論之研究,頁87-88,國立成功大學法律學系碩士論文,2016年7月。
[31] 同前註,頁87
[32] 吳景芳,同註2,頁100-101。
[33] 郭豫珍,量刑與刑量:量刑輔助制度的全觀微視,元照,頁191-192,2013年7 月。
[34] 同前註,頁193-194。
[35] 梁家昊,同註30,頁85。
[36] 郭豫珍,同註33,頁192-193。
[37] 郭豫珍,同註33,頁202。
[38] 林山田,刑法通論(下),自版,頁525以下,2008年1月增訂10版。
[39] 許宗力,從大法官解釋看平等原則與違憲審查,載:憲法解釋之理論與實務第二輯,新學林,頁86,2000年8月。
[40] 最高法院88年台上字第328號刑事判決之要旨謂:「緩刑之宣告與否,乃實體法上賦予法院得為自由裁量之事項,法院行使此項職權時,固應受比例原則與平等原則等一般法律原則之支配……之價值要求,不得逾越此等特性之程度,用 以維護其均衡;而所謂平等原則,非指一律齊頭之平等待遇,應從實質上加以客 觀判斷,對相同之條件事實,始得為相同之處理」。
[41] 蘇凱平,以平等原則建立量刑原則的意義與價值:臺灣高等法院105年度交上易字第117號刑事判決評析,台灣法學雜誌,第393期,頁34,2020年6月。
[42] 參考司法院的新聞稿,刑事案件量刑委員會研議委員會新聞稿,2020年10月7日,參見網址:https://www.judicial.gov.tw/tw/cp-1887-146463-f6c8f-1.html(最後瀏覽日:2023年8月24日)。
[43] 溫祖德,量刑程序被告基本權之保障──從美國量刑程序被告基本權之考察, 台灣法律人,第33期,頁53-71,2024年3月。
[44] 亦即在量刑程序,使檢察官證明事實至優勢證據程度得以滿足正當法律程序之要求。舉例言之,被告之前科紀錄為量刑因子,檢察官毋庸證明被告之前科紀錄至超越合理懷疑之程度。同前註,頁67。
[45] 亦即若有使用加重刑罰要件,超越原本認定犯罪事實之罪法定最高刑度,此已經等同於另一個犯罪,故被告受有「超越合理懷疑之證明程度」認定該「加重刑罰要件」事實之保護。溫祖德,同註43,頁68。
[46] 溫祖德,同註43,頁69-70。
[47] 相關的應用不只是在司法領域,也可以應用於其他各種文字資料。舉例來說, 在醫療方面可以參考Craig H. Ganoe, Weiyi Wu, Paul J. Barr, William Haslett, Michelle D. Dannenberg, Kyra L. Bonasia, James C. Finora, Jesse A. Schoonmaker,
Wambui M. Onsando, James Ryan, Glyn Elwyn, Martha L. Bruce, Amar K. Das & Saeed Hassanpour, Natural Language Processing for Automated Annotation of Medication Mentions in Primary Care Visit Conversations, 4(3) JAMIA Open ooab071 (2021).
[48] 同註8。
[49] 這樣的分類方式有助於評斷個別因素的語意類型,有助於進一步的分析判斷。類似的標註方式也已經應用於離婚後親權酌定案件的裁判預測。可參考Yining Juan, Chung-Chi Chen, Hsin-His Chen & Daw-Wei Wang, CustodiAI: A System for Predicting Child Custody Outcomes, in PROCEEDINGS OF THE 13TH INTERNATIONAL JOINT CONFERENCE ON NATURAL LANGUAGE PROCESSING AND THE 3RD CONFERENCE OF THE ASIA-PACIFIC CHAPTER OF THE ASSOCIATION FOR COMPUTATIONAL LINGUISTICS: SYSTEM DEMONSTRATIONS 10-16 (2023).
[50] 關於詞向量的技術原理的簡要介紹可參考以下科普文章,阿Han,來認識一下詞向量(Word Embedding or Word Vector)吧,阿Han的軟體技術棧,2023年6 月6 日,綱址: https://vocus.cc/article/6471799dfd89780001604a5b ( 最後瀏覽日:2023年12月24日)。繁體中文資料庫的相關說明可參考中央研究院詞庫小組,中文向量表達,網址:https://ckip.iis.sinica.edu.tw/project/embedding(最後瀏覽日:2023年12月24日)。
[51] David E. Rumelhart, Geoffrey E. Hinton & Ronald J. Williams, Learning
Representations by Back-Propagating Errors, 323(6088) NATURE 533-36 (1986).
[52] 一般而言,CNN多是應用於圖像辨識的功能。但是後來發現應用於自然語言處理也是有相當好的成效,例如可參考Ronan Collobert & Jason Weston, A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning, in PROCEEDINGS OF THE 25TH INTERNATIONAL CONFERENCE ON MACHINE LEARNING 160-67 (2008).
[53] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan
Gomez, Lukasz Kaiser & Illia Polosukhin, Attention Is All You Need, in ADVANCES IN NEURAL INFORMATION PROCESSING SYSTEMS 6000-10 (2017).
[54] Jacob Devlin, Ming-Wei Chang, Kenton Lee & Kristina Toutanova, BERT: Pre- training of Deep Bidirectional Transformers for Language Understanding, Cite as: arXiv:1810.04805v2: https://doi.org/10.48550/arXiv.1810.04805 (Oct. 11, 2018, last visited: Dec. 24, 2023).
[55] 關於BERT的技術原理的簡要介紹可參考以下科普文章:Meng Lee,進擊的BERT:NLP界的巨人之力與遷移學習,個人部落格,2019年7月10日,網址: https://leemeng.tw/attack_on_bert_transfer_learning_in_nlp.html ( 最後瀏覽日: 2023年8月24日)。
[56] 關於BERT與GPT的Transformer的不同,可參考以下科普文章:Peter Li,從
BERT到GPT模型帶您綜觀大型語言模型(LLM):編碼器(Encoder-only), 編碼器解碼器(Encoder-Decoder),解碼器方法(Decoder),個人部落格, 2023年10月11日,網址:https://peterlihouse.com/%E9%A6%96%E9%A0% 81/%E7%9F%A5%E8%AD%98%E5%88%86%E4%BA%AB/%E4%BA%BA%E5
%B7%A5%E6%99%BA%E6%85%A7/%E5%BE%9Ebert%E5%88%B0gpt%E6% A8%A1%E5%9E%8B%E5%B8%B6%E6%82%A8%E7%B6%9C%E8%A7%80%E 5%A4%A7%E5%9E%8B%E8%AA%9E%E8%A8%80%E6%A8%A1%E5%9E%8 Bllm%EF%BC%9A%E7%B7%A8%E7%A2%BC%E5%99%A8encoder-only%EF
%BC%8C/(最後瀏覽日:2024年7月17日)。
[57] 相關研究可參見吳晨皓,BERT與GPT-2分別應用於刑事案件之罪名分類及判決書生成,頁1以下,國立高雄科技大學資訊管理系碩士論文,2020年5月。
[58] 相關研究可參見謝閎宇,基於深度學習模型之刑事判決書情境萃取研究,頁1
以下,國立中興大學資訊工程學系碩士論文,2021年1月。
[59] 同註8。
[60] 同註10。
[61] 李榮耕,初探刑事程序法的人工智慧應用──以犯罪熱區為例,載:人工智慧相關法律議題芻議,元照,頁141-146,2020年8月。
[62] 李榮耕,刑事程序中人工智慧於風險評估上的應用,政大法學評論,第168 期,頁156-157,2022年3月。
參考文獻
一、中文部分
(一)專書
林山田,刑法通論(下),自版,2008年1月增訂10版。
Lin, Shan-Tien, General Theory of Criminal Law (II), Self-published (rev. 10th ed. 2008).
陳誌雄、楊哲銘、李崇僖,人工智慧與相關法律議題,元照,2019年9月。
Chen, Chih-Hsiung, Yang, Che-Ming & Lee, Chung-Hsi, Artificial Intelligence and Related Legal Issues, Angle Publishing (2019).
郭豫珍,量刑與刑量:量刑輔助制度的全觀微視,元照,2013年7月。
Kuo, Yu-Chen, Sentencing and Degree of Punishment: A Holistic Microcosmic View of the Sentencing Assistance System, Angle Publishing (2013).
(二)期刊論文
文家倩,量刑與AI的交會──淺談司法院量刑資訊系統的革新, 當代法律,第10期,頁6-12,2022年10月。
Wen, Chia-Chien, The Meeting of Sentencing and AI—An Introduction to the Innovation of the Judicial Yuan’s Sentencing Information System, 10 Contemporary Law Journal 6 (2022).
王紀軒,人工智慧於司法實務的應用,月旦法學雜誌,第293期,頁93-114,2019年9月。
Wang, Chi-Hsuan, Application of Artificial Intelligence in Judicial Practice in Taiwan, 293 The Taiwan Law Review 93 (2019).
王道維、邱筱涵,當ChatGPT來敲法官的門──淺談AI應用於司法審判的原則與方式,當代法律,第18期,頁6-28,2023年6月。Wang, Daw-Wei & Chiu, Hsiao-Han, When ChatGPT Knocks on the Judge’s Door—A Brief Discussion on the Principles and Methods of Applying AI to Judicial Trials, 18 Contemporary Law Journal 6 (2023).
李榮耕,刑事程序中人工智慧於風險評估上的應用,政大法學評論,第168期,頁117-186,2022年3月。
Li, Rong-Geng, AI Risk Assessment in Criminal Justice, 168 Chengchi Law Review 117 (2022).
溫祖德,量刑程序被告基本權之保障──從美國量刑程序被告基本權之考察,台灣法律人,第33期,頁53-71,2024年3月。
Wen, Tzu-Te, Guarantees of Basic Rights of Defendants in Sentencing Procedures—An Examination of the Basic Rights of Defendants in Sentencing Procedures in the United States, 33 Formosan Jurist 53 (2024).
蘇凱平,以平等原則建立量刑原則的意義與價值:臺灣高等法院105年度交上易字第117號刑事判決評析,台灣法學雜誌,第393 期,頁31-42,2020年6月。
Su, Kai-Ping, The Meaning and Value of Establishing the Principle of Sentencing by the Principle of Equality: An Analysis on Taiwan High Court Criminal Judgment 105 Jiaoshang Yi Zi No. 117, 393 Taiwan Law Journal 31 (2020).
龍建宇、莊弘鈺,人工智慧於司法實務之可能運用與挑戰,國立中正大學法學集刊,第62期,頁43-66,2019年1月。
Long, Chien-Yu & Chuang, Hung-Yu, Possible Application and Challenge of Artificial Intelligence in Judicial Practice, 62 National Chung Chen University Law Journal 43 (2019).
蕭奕弘,人工智慧之新發展與在司法實務上之應用,檢察新論,第25期,頁3-27,2019年2月。
Hsiao, I-Hung, The New Development of Artificial Intelligence and Its Application in Judicial Practice, 25 Taiwan Prosecutor Review 3 (2019).
(三)專書論文
吳景芳,美國之聯邦量刑改革法,載:刑事政策與犯罪研究論文集(三),司法官學院犯罪防治研究中心,頁19-41,2000年11月。Wu, Jing-Fang, The Federal Sentencing Reform Act in the UnitedStates, in: Criminal Policy and Crime Research Papers (III), 19, (Crime Prevention Research Center, Academy for the Judiciary, Ministry of Justice ed., 2000).
李榮耕,初探刑事程序法的人工智慧應用──以犯罪熱區為例,載:人工智慧相關法律議題芻議,元照,頁117-148,2020年8月。Li, Rong-Geng, A First Look at the Application of Artificial Intelligence in Criminal Procedural Law—A Crime Hotspot as an Example, in Preliminary Discussion on Legal Issues Related to Artificial Intelligence, 117, Angle Publishing (Liu, Ching-Yi ed., 2020).
許宗力,從大法官解釋看平等原則與違憲審查,載:憲法解釋之理論與實務第二輯,新學林,頁85-122,2000年8月。
Hsu, Tzong-Li, Equality Principles and Unconstitutional Review in the Light of J.Y. Interpretation, in Theories and Practices of Constitutional Interpretation (II), 85, New Sharing (Lee, Chien-Liang & Chien, Tze- Shiou eds., 2000).
二、英文部分
(一)期刊論文
Ganoe, Craig H., Wu, Weiyi, Barr, Paul J., Haslett, William, Dannenberg, Michelle D., Bonasia, Kyra L., Finora, James C., Schoonmaker, Jesse A., Onsando, Wambui M., Ryan, James, Elwyn, Glyn, Bruce, Martha L., Das, Amar K. & Hassanpour, Saeed, Natural Language Processing for Automated Annotation of Medication Mentions in Primary Care Visit Conversations, 4(3) JAMIA Open ooab071 (2021).
Katz, Daniel Martin, Bommarito, Michael J. & Blackman, Josh, A General Approach for Predicting the Behavior of the Supreme Court of the United States, 12(4) Plos One e0174698 (2017).
Lage-Freitas, André, Allende-Cid, Héctor, Santana, Orivaldo & Oliveira-Lage, Lívia, Predicting Brazilian Court Decisions, 8 PeerJ Computer Science e904 (2022).
Rumelhart, David E., Hinton, Geoffrey E. & Williams, Ronald J., Learning Representations by Back-Propagating Errors, 323(6088) Nature 533 (1986).
(二)專書論文
Collobert, Ronan & Weston, Jason, A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning, in Proceedings of the 25th International Conference on Machine Learning, 160, ACM (2008).
Juan, Yining, Chen, Chung-Chi, Chen, Hsin-His & Wang, Daw-Wei, CustodiAI: A System for Predicting Child Custody Outcomes, in Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-PacificChapter of the Association for Computational Linguistics: System Demonstrations, 10 (2023).
Kowsrihawat, Kankawin, Vateekul, Peerapon & Boonkwan, Prachya, Predicting Judicial Decisions of Criminal Cases from Thai Supreme Court Using Bi-Directional GRU with Attention Mechanism, in 2018 5th Asian Conference on Defense Technology (ACDT), 50, IEEE (2018).
Vaswani, Ashish, Shazeer, Noam, Parmar, Niki, Uszkoreit, Jakob, Jones, Llion, Gomez, Aidan N., Kaiser, Lukasz & Polosukhin, Illia, Attention Is All You Need, in Advances in Neural Information Processing Systems, 6000 (2017).
Virtucio, Michael Benedict L., Aborot, Jeffrey A., Abonita, John Kevin C., Avinante, Roxanne S., Copino, Rother Jay B., Neverida, Michelle P., Osiana, Vanesa O., Peramo, Elmer C., Syjuco, Joanna G. & Tan, Glenn, Brian A., Predicting Decisions of the Philippine Supreme Court Using Natural Language Processing and Machine Learning, in 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), vol. 2, at 130, IEEE (2018).
Zhong, Haoxi, Guo, Zhipeng, Tu, Cunchao, Xiao, Chaojun, Liu, Zhiyuan & Sun, Maosong, Legal Judgment Prediction via Topological Learning, in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 3540 (2018).





下一則: 臺灣新竹地方法院邀請清華大學王教授道維到院為家事調解委員講授「生成式AI落地應用於家事調解」新聞稿










