機器學習作資料學習或訓練模型前,都有一個必要的步驟叫做資料標記(Data Tag),就是必須知道待辨識影像中目標訊息的標準答案!好像題庫的標準答案,這樣用程式不斷調整模型反覆辨識猜答案時才能很快的自動比對答案對不對?最終就是要用嘗試錯誤的方式調整出辨識率最高的模型!
當然毫無規範與方向的任意嘗試錯誤要找到好的(正確的)模型有如大海撈針!所以即使你用機器學習做產品研發也不是那麼浪漫,只要有足夠的有資料就可以自動產出好結果的!其實需要做的工作也跟不用機器學習的我很類似,就是必須依據影像辨識的原理,盡可能設計出接近事實原理的模型。
當辨識結果一團亂無法收斂時,機器學習「專家」也必須了解學習會迷路的原因,讓模型往正確的方向調整演化!這就是所謂的「監督式」學習了!如何監督呢?要監督甚麼事項呢?基本上還是要根據影像辨識的基本原理!所以到最後要能做出堪用的影像辨識產品,你需要知道的影像辨識原理就跟我差不多了!
既然你都很熟知影像辨識原理,也充分掌握研究資料特性時,當然就可以不必這麼麻煩操作機器學習了!就學我一樣,直接用你知道的明確的影像辨識原理,直接寫出最精簡準確的辨識程式不就好了嗎?所以我常說以影像辨識來說,機器學習或深度學習都是脫了褲子放屁,多此一舉!
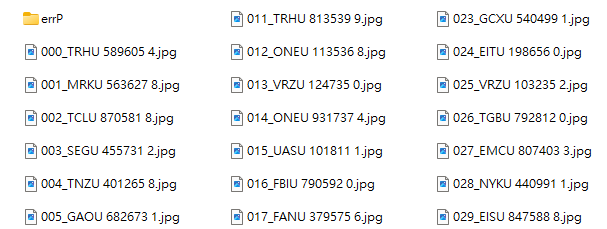
但是我的研究過程中,其實也會做資料標記的!如上目錄,我有數百張貨櫃碼的影像,也設計了可以辨識貨櫃碼的程式,但是程式的主支流程很多很複雜,要知道每個細節流程是否有效?是不是對所有資料都有效?還要知道每一個例外處理會不會影響到不相干的案例?讓原本可以辨識對的反而產生錯誤?
我也必須有個快速測試的機制,很像器學習的訓練過程!全部資料跑一次,然後除了跟機器學習一樣會看整體辨識率之外,我還會將錯誤資料另行拷貝到特定的目錄(如上的errP)做後續的個案分析!由具體的辨識錯誤過程中決定修改模型的下一步!機器學習就不太重視個案分析了!嘗試錯誤亂槍打鳥比較是他們喜歡的SOP!結果對就好了,他們是不研究科學的!
如上目錄我的標準做法就是系統化的更改影像檔名,第一段落是資料序號,第二段落就是標準答案了!我用程式批次呼叫辨識這些檔案時,每個辨識結果跟檔名比較就知道對錯了!原本一張一張手動操作辨識分類,跑一個回合就是幾個小時甚至一整天!還會超量使用滑鼠弄到手腕受傷,利用這種標記的方式,做一回合的實驗只需要幾分鐘!把大部分的時間留給真正需要動腦的個案研究分析!
所以任何研究方法都是會依據現實需要而逐漸殊途同歸的!我會學習機器學習派的系統化資料處理方式,機器學習派也不能對影像辨識原理一無所知,不然工作效率就會低到甚麼東西都做不出來!所以他們一樣必須好好讀書學習相關的知識原理,絕對不是有資料就無所不能萬事OK的!
重點是:以影像辨識來說,如果你的目標是辨識率98%,就一定要將所有細節原理與資料特性都精確掌握,精準設計程式(或稱模型)才有可能做到!既然所有細節成因與特徵都必須知道,那就根本不需要讓資料做學習訓練了!因為那種方式只能跑出不夠精確的推測模型,還是無法達到實用標準的!徒然浪費了你和電腦的時間而已!直接按照辨識邏輯寫程式吧!為了機器學習而機器學習?為了AI而AI?那是愚不可及的!









限會員,要發表迴響,請先登入


