
這是我使用332張手拍貨櫃碼影像辨識實驗的成績!很驚人的,只有一張過度歪斜還嚴重反光的照片無法辨識,其他照片即使有些失焦模糊或歪斜變形都逃不過我的法眼!而且經過優化調整,約1.3M畫素,畫面還很複雜很多字的影像,平均不到0.1秒(95.3毫秒)就可以辨識完成!
怎麼作到的?最關鍵的技術重點就是:不要用ML、DL與CNN!因為這些技術的基底是統計學,先天就是用來「估計」,而非精準「解題」用的數學!所以不可能穩定精準是必然的!還必須用到很大量的資料,以及很大量的回歸統計運算,才能產生較為穩定的結果!簡單說,就是需要的成本很高,需要的研發時間很長!但是一定不會準確到接近我們需要的高辨識率!碰到真實世界的資料,辨識率能到八九成就很偷笑了!95%以上根本就是奇蹟了!
最可怕的可能還不是這些!因為上述的問題屬於軟體開發的階段,如果開發成功的軟體真的很準很好用就沒問題了!但事實當然不是這樣的!這些所謂的AI影像辨識,第一步的前處理就是使用CNN掃描全圖(Convolution)收集資訊!光是這一步驟的運算量就是我使用傳統OCR技術作辨識的數十倍之多了!更不用說之後的隱藏層與全連結層的深度學習運算還會需要更大量的運算!
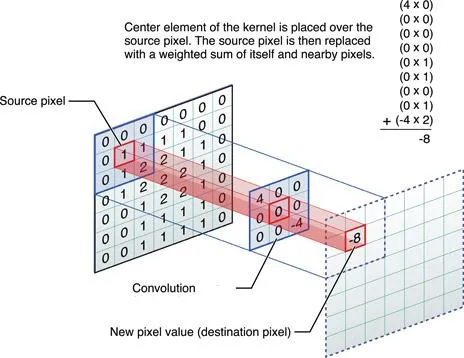
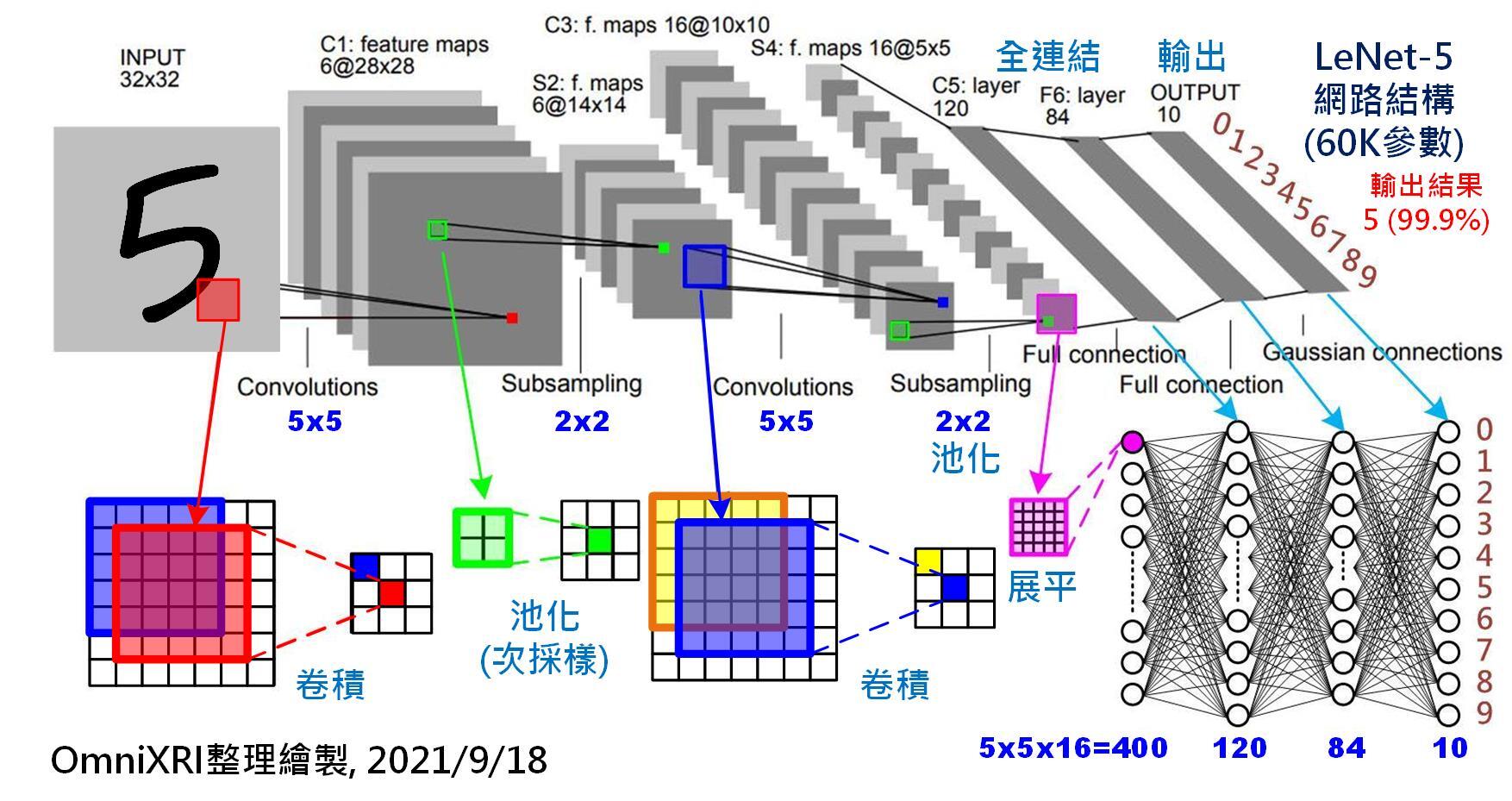
所以使用這些需要爆量計算量的技術作影像辨識實在是個大災難與大錢坑!沒有額外的GPU算力支援就根本無法運作!這完全是理論上就吃力不討好的愚蠢技術!因為我前面說過了!他們是統計學,先天就不可能很準確的!那你們花那麼多錢做這種一般客戶根本買不起,還不是很準確的辨識軟體有甚麼意義嗎?其實國王身上根本沒有新衣,我只是不願說謊的天真孩子!
或許現在開始有比較多人同意我的看法了!我的這本完全不談ML、DL與CNN的影像辨識書居然賣到缺貨?前幾天出版商剛找我簽約要加印了!事實勝於雄辯嘛!因為使用ML、DL與CNN的所謂AI技術很久,卻始終無法做出可用影像辨識軟體的人越來越多了!他們如果看到我的成功就一定會轉向來了解我是怎麼辦到的了!

事實上不用ML、DL與CNN的影像辨識技術一直都擺在那裡!也始終不曾落伍變得不實用!我也是三十年前就看著書本學會這些技術的!現在只是做更複雜的整合應用而已!但是面對ML、DL與CNN進軍影像辨識領域撲天蓋地的宣傳攻勢,我的這本書幾乎是目前書市上唯一倖存,但是即將絕種的瀕危動物了!
你相信嗎?這本書以「影像辨識」為標題,卻與ML、DL或CNN毫無關係?書中完全沒談到這些似乎很熱門的東西!當然裡面也沒有Python!因為Python是執行效能最低速度最慢的程式語言,非常不適合需要高速計算的影像辨識的!我當然不會用它!這實在很詭異?好像太反「AI」潮流了!但遲早大家會認同,這樣才是對的!這樣才是最專業有效的實用好書!也是最AI的影像辨識解決方案!




限會員,要發表迴響,請先登入


