
天天研究車牌辨識快10年了,如前文所述,有百萬種讓你辨識錯誤的原因,所以我的研究也就有10年都做不完的議題!進入百萬畫素的時代之後,車牌辨識不再是從簡單的車牌特寫影像中辨識車牌,所有複雜的背景都可以輕鬆拍到,使用者也自然會期待從「自然影像」,就是不是特地為辨識車牌的影像中把車牌辨識出來!
在百萬畫素複雜背景中快速正確找到車牌的技術是我事業奠基的起點,我比其他車牌辨識研發廠商大約早了兩年適應了百萬畫素全景辨識車牌的新時代,也因此賺到了我的第一桶金,其實是藉此還清了創業之初經營不善的幾百萬負債。但即使找車牌的技術不錯了,在正確辨識字元上還是要面對一些傳統的老問題。
在台灣所有做過或用過車牌辨識的人大概都知道,六碼車牌中的B8與D0很容易交叉誤認,七碼車牌當然已經吸收了歷史的教訓,一開始設計時就避開了這個問題。如七碼車牌ABC-5678,英數字分別在兩個區段,英文區沒有數字,數字區沒有英文,所以在英文區看到8就直接改成B,在數字區看到B就改成8!D與0的狀況也一樣!甚至監理單位公告了,容易與數字01交叉誤認的英文I與O字元是根本不會使用的!所以七碼車牌先天上就沒有B8D0誤認的問題!
大家可能沒注意到的還有六碼車牌的689其實也很近似,如果影像中的字小一點,一個缺口之差就是另一個字了!所以七碼車牌的69就變成69了!689之間筆畫差異變大就不可能認錯了!但是有點奇怪的是為何把3和5弄得好像?現在七碼車牌的數字會誤認的很少,就只有遠距離時3與5之間的誤認了!

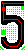
回頭說到六碼(含以下)車牌就是所有車牌辨識研發者的噩夢了!字元區段的規則亂七八糟,2-4、4-2、3-3、2-3、3-2,甚至2-2都可以!雖然都是兩段式的,但是唯一可靠的英數字區隔是:3字(含)以上的長區段必然是全數字,其餘短區段內英數字都可以交雜在一起。
糟糕的是B869D0等字型設計時沒有刻意做差異化,譬如數字0與英文字母O在六碼車牌中都會出現,但形狀卻完全一樣!我質問某監理站長某車牌應視為D0-????或DO-????時,時他才尷尬回應英數字混合區段出現的都視為英文字母O啦!甚至監理單位根本沒公告六碼的車牌標準字型!這個離奇事你們知道嗎?
雖然現在監理單位不會再發放六碼車牌了,但是汽車如果保養得宜可以開上幾十年的!監理單位似乎也無意全面回收更換舊車牌?所以未來很多年間正確辨識六碼車牌還是我日常工作的一部份,我無法迴避這個B8與DO交叉誤認的老問題!至少辨識結果要與人的視覺判斷非常接近!我現有版本的誤認已經很少了,但是我主要挑戰的是道路版辨識更遠更小的車牌,我還希望我的辨識更AI!
所以我有刻意彙整這些可能有B8或DO誤認的車牌影像,事實上有一千多張!針對這些影像我會苦思為何人的眼睛會判斷是B或8?因為放大來看真的很相似啊!我的字模比對碰到如上案例就是在辨識錯誤的邊緣了!
怎麼辦呢?其實就是要建立一些量化的「特徵」了!譬如字元的左上與左下的兩個角落是偏向圓角還是尖角?左邊的腰部有沒有曲度腰身?等等。我發現人眼就是根據這些細微的特徵判斷是B或8的!所以我必須將這些特徵轉換成數學公式與程式,再用這些收集的影像範例調整決定判斷B或8的門檻!

你可以稱它們為局部的機器學習,但是顯然如果要做這麼細緻的設計,機器學習就不會如此吸引那些擺明了想偷懶的人了!我認為問題就擺在那邊,要解決問題遲早都必須走到那麼精確細緻的地步!你以為機器學習是可以偷懶不必傷腦筋的捷徑嗎?別傻了!大範圍的資料訓練或學習,絕對學不到那麼小而關鍵的特徵的!





限會員,要發表迴響,請先登入


