
老實說,即使一般人用眼睛看這個車牌都可能看錯,譬如看成MMM或WWW三連星,或是MWW,因為W開頭的車牌是殘障專用車牌很少見,所以多數人會自動認定第一個字一定是M至於後面兩字真的好難區分!即使放大來看都會覺得形狀真的差不多!
前文提到:影像是立體世界的平面投影,事實上不只如此!攝影機的焦距準確與否?解析度夠不夠?環境亮度是不是太強或太弱?原始影像作串流壓縮,或是JPG檔案壓縮時,都會讓我們想要辨識的字元目標產生邊緣模糊的變形效應!所以就會讓本來就很像的M與W更相似,更容易魚目混珠交叉誤認了!
但是請大家設想一下,如上圖這種清晰程度,實際的畫素字元高度也達到31畫素了!如果我的車牌辨識軟體卻有一半的機會誤認M與W,那我還想在「道上」混嗎?老是要跟客戶解釋為何認錯真的很麻煩,也有損鄉下老師英明睿智的形象!所以即使很困難,我也必須將如上的辨識正確率提高到90%以上才行!
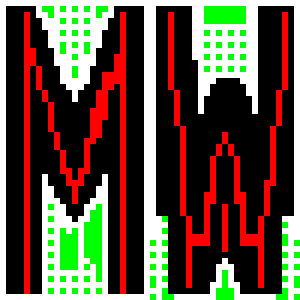
首先我們發明了有點複雜的特徵字模比對法!不敢掠美,這是我的RD發明的!不是我!此法兼顧了筆畫特徵與字模比對兩種字元辨識方法的優點,紅色點如果點中實際影像的筆劃黑區,或綠色點點中實際影像的空白區,就會加分,黑色區則是被忽略的!因為對於筆畫顯示它們是甚麼字?影響不大。
即使如此,大家看看真實影像中被模糊化之後抓出來的M與W,模糊的狀況還是令人擔憂的!事實上誤認情況還是時常出現,所以必須加上更多的「特徵」加權,幫我們判斷是M或W?這很像大學生多元入學的申請過程,如果你在正常成績表現之外,能提出其他相關表現的資訊,就可以加分得到一點優勢了!
這一部份我能用的資訊其實是不太明確的!有點像機器學習的機率統計概念,譬如M「傾向」於上下等寬!W「傾向」於上寬下窄,但是在有限的解析度與清晰度之下,因為數位取樣的截斷誤差(Truncation error)這個特徵不保證正確!甚至有時候一個突出的雜點就改變了字元的寬度了!換言之,上下等寬不保證是M,上寬下窄也未必一定是W!
所以我們會根據較大量的資料案例,經過經驗統計建立一個特徵加權的機制,上下寬窄等特徵並不是決定性的因素,但是可以參考加減分的意思!事實上是加入這類機制後,對於原本清楚的字元影像辨識結果影響不大,但是模糊邊緣的影像字元辨識率就提高很多了!所以不必懷疑,如上的案例,我的辨識正確率甚至高於人眼的第一時間快速判斷!
這就是我作車牌很厲害的「商業機密」了!這一部份或許也可以說我是用到機器學習(ML)的概念了!只要可以幫我提昇辨識率任何有效的方法我都不會因噎廢食的!當所有可以明確定量的資訊都用完了,當然那些不穩定不明確的參考資料也不能浪費的!有比沒有好,Better than nothing嘛!
我天天罵ML的原因並不是它們根本沒用!而是它們被喧賓奪主的瞎捧成為影像辨識技術的主體與主導地位?這就太荒謬了!知之為知之,不知為不知!ML應該處理的範圍是那些知與不知的不明確資訊,就像我現在做的事情!明確資訊應該是影像辨識的主體,確定無效的資訊應該排除!模糊地帶的不確定資訊才是應該用ML處理的部分!
就像大學招生吧!學生課外活動的「參考」資料確實有意義,但是如果「只看」參考資料,完全拋棄正規的考試與學業成績呢?那是很奇怪的想法!以影像辨識來說,就是傳統的技術如OCR等根本就是穩定可靠的基礎,ML、DL與CNN等技術並未證明可以取代其所有功效,就直接篡位變成影像辨識「唯一」的主角了?
這實在太奇怪了!也必定會是影像辨識技術發展史上的大災難!還好,我只是一間私人公司,愛怎麼作影像處理都行!只要能做出客戶滿意的辨識軟體即可!那些被迫為了AI而AI的大廠商與頂尖大學研究單位呢?他們就是如同土耳其大地震的重災區了!我住的是自己蓋的堅固獨立屋,不是那種豆腐渣工程的大樓啦!我的房子不會突然意外倒塌的!ML、DL與CNN呢?我覺得就是會!












限會員,要發表迴響,請先登入


