
台灣的七碼車牌是有根據影像辨識的需要特別設計的!在格式與字型的規定上就完全避開了B8、D0、689、I1與O0等等相似字形的交叉誤認,譬如前段一定是英文,後段一定是數字,就不可能有B與8的誤認了!甚至規則上直接明定不會使用英文字母的I與O字元!當然這些貼心的規定會讓我們這些做辨識的人非常紓壓!
但是當目標太小時還是會碰到一些尷尬的誤認!像上面的3字遠看時就常被誤認為5了!畫素不夠呈現出那個3的上半部轉折筆畫嘛!所以只看二值化後的字元圖真的是比較像5而不是3,把它跟標準字模並列比較是如下圖這樣的:
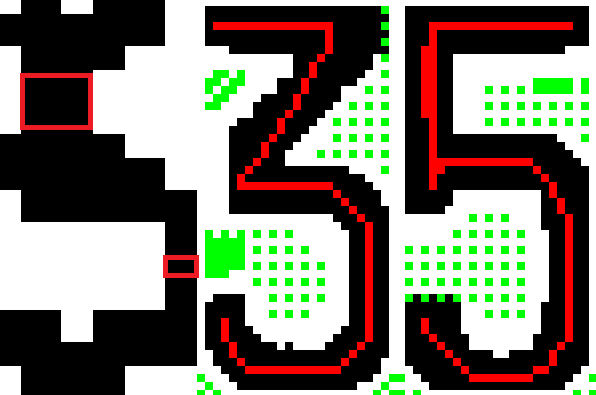
當然這跟JPG壓縮時產生的平滑化效應也有關係的!而且我們還要做車牌歪斜變形時的幾何校正處理,數位影像運算時產生的截斷誤差(Truncation error)稍一偏差一兩個畫素,就更難確認是誰了!如果只因為這個字弄錯讓整個辨識功虧一簣當然是很吐血的!
怎麼辦呢?這時候就要靠一些非常規的資料統計的經驗了!所謂的機器學習大致上也就是會用大量資料累積這種經驗,也就是在無法辨識3字的轉折筆畫之下,還是能找到特徵加權協助我們判斷是3還是5?
因為我看過很多類似資料,所以不必真的去跑機器學習就可以得到一個特徵了:如上畫的兩個小方框,假的5上面那個垂直筆畫會特別粗!大約是右下方正常的直線筆畫的兩倍粗!根據這個特徵考慮就不會被騙了!兩個垂直筆畫一般粗時就是5,上粗下窄就是3了!
以這種非常侷限的範圍內來看,我也是有用到機器學習的統計概念的!但是如果大部分的辨識邏輯都要靠資料統計?就是所謂的深度學習?那實在是太太太沒效率了!直接用數學物理觀念建立適當的演算法當然會快速也準確很多!統計學本來就是在確定的知識不足,或資料的不確定性高時用來輔助判斷的技術!
簡單說,用最經濟有效的方法達到目的才是最聰明的作法!絕對沒有哪種技術方法可以被視為AI的主要技術,其他技術就不是AI的!如果有人跟你說有「AI技術」?那鐵定就是別有居心想騙你買甚麼其實可以不必使用的軟硬體而已!別輕易上當了!









限會員,要發表迴響,請先登入


