
碰到車牌在陽光下產生強烈反光是一個戶外車牌辨識的大麻煩!原本筆畫漆黑的字元會變成很奇怪的空心字?原因是多數車牌字元的設計是略為突出表面的,所以字元筆畫的邊緣會有陰影。也還好有這個立體設計,讓反光時多半還能呈現字元輪廓,否則更難看到字元。
當然如果反光強到一定程度,影像曝光到超過攝影機的感光極限時,會連輪廓都看不到,那就神仙也救不了了!市面上有些非法的方式可以讓車牌在警方蒐證的監視器中看不到字元,主要就是塗上容易反光的特殊油漆或貼上透明貼紙加強這種效應,讓車牌特別容易因為反光導致無法辨識的意思。

我們做來比對字元的字模當然都是實心的,所以比對出來的結果當然很難正確!置頂圖的最上方是尚有輪廓足以完成辨識的原圖,中間是二值化加上對整個「車牌」作了幾何校正後的影像,左邊的三個字還好,右邊的四個數字都呈現空心狀態,人眼辨識是沒有問題,但辨識軟體如果不做特殊的處理就很容易辨識錯誤了!
我的程序會在此二值化圖中挖出個別字元,再做一次「字元」的幾何校正成字模的大小,這個步驟只要有輪廓就可以做得正確,但是接下來的字模比對,因為是空心狀態就很難得到正確答案!怎麼辦呢?我會想如果可以在這個字模的範圍內再做一次更高門檻的二值化,或許字元就會至少部份變回實心了!通常筆畫內的反光區還是略黑於車牌背景的純白色的!
但是原來的程序經過兩次幾何校正程序,原始的灰階強度值已經遺失了!也就是跟著變形的只有二值化的黑白資料,沒有字模大小的灰階資訊了!那還不簡單?就是回頭改程式,讓幾何校正的程序也一路帶著灰階資訊走到變成字模大小的階段!
接下來我可以統計一個字模大小內的黑點覆蓋率,一般實心字的覆蓋率大約是40%,明顯太低的就可能是受到反光影響只剩下輪廓的空心字了!也就是我發現病人出現生病的症狀了!那就拿灰階資料重做二值化,就是提高二值化門檻,強迫黑點覆蓋要多到大約40%啦!
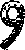
如上圖就是字元9重做二值化之後的結果,這個狀態要正確辨識為9當然就沒問題了!不必非要全部填滿不可的!只要不會誤認為另一個字就算夠清楚了!這就是我作影像辨識的理念!任何的辨識錯誤或失敗都應該追究原因,找到原因針對問題建立例外處理程序重整資料,通常就可以得到正確的辨識答案!SOP無法直接辨識的,就是要增加針對錯誤的例外處理啦!
所以我的影像辨識真的很像醫療體系,SOP是給一般健康的人,也就是清晰好辨識的影像用的!但是我們必須隨時保持警覺做各種檢驗偵測,發現身體有異常的症狀就要對症下藥準確治療,如果每個病例都能預防或治好,就是讓更多人保持健康不會死掉!對影像辨識系統來說就是異常狀態的局部影像可以被感知,並獲得特殊的強化處理,整體辨識率就會提高了!
但是現在流行的,以機器學習為基礎的所謂AI影像辨識的概念是很不相同的!他們比較像是在找一個萬靈丹!任何人不管有病沒病都強迫吃一樣的藥,都走同一個SOP,希望有病治病,無病也可以強身的意思!所謂的學習訓練就是先設計一個概略的數學模型,然後用大量以人眼辨識後寫上標準答案的(標記)資料去塑造(回歸調整)出有最高正確率的模型!
但是資料的自行磨合能否產生如人類依據科學原理思考產生的視覺智慧?這是一個幾乎不可能的期待!成功機率是很低很低的!即使真的做得到,也必須花非常多的錢與時間!大部分的結果是投資很大還是一無所獲!所以奉勸天真受騙中的影像辨識學習者!還是不要對ML、DL與CNN有不合理的期待!它們用處不大的!要解題還是從物理原理著手比較實際有效!
另一方面,萬靈丹式的思維會讓處理程序產生極大的浪費!沒病的人如果也天天上醫院看病有意義嗎?醫療資源會夠用嗎?須知機器學習做出來的影像辨識模型辨識率越高就表示隱含的資源浪費越大!因為不管是好辨識或不好辨識的影像處理程序都完全一樣!沒有快速通關的便道!它們的主體架構就是這樣的!不能因材施教對症下藥有彈性的系統其實是很糟糕,極度不環保的,它們絕對不夠格,也不應該被稱為AI影像辨識技術的主流!








限會員,要發表迴響,請先登入


