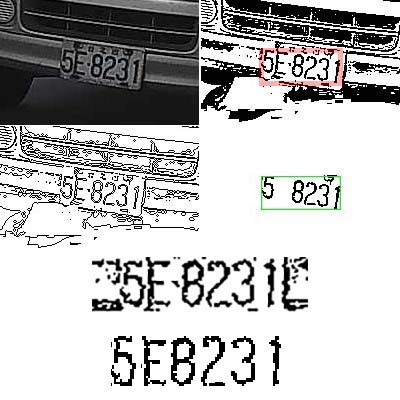
上面是我辨識一張髒污車牌的程序連環漫畫,當我根據各種原理與資訊把影像逐步處理到最下圖的程度,再參考台灣車牌應有的英數字格式規範,就可以得到正確的答案5E-8231了!我刻意秀出這個連環漫畫是希望讀者可以充分體會到:要辨識出不清楚的目標,絕對必須是一個精密的思考過程!也就是逐步進行的合理影像處理過程!你想光靠CNN掃描統計的特徵資訊就一步就到位猜對每一個字?那種機率比買樂透還低!
現在的AI影像辨識的宣傳廣告已經把多數人洗腦到以為:只要資料夠多,就一定可以經過機器學習產生出跟人一樣,甚至更好的視覺智慧?事實上呢?這種事即使理論上無法否定其「可能性」,但現實上從未發生過!因為視覺智慧實在太複雜了,要光靠經驗學習辨識難辨識的目標,資料是永遠不夠的!
就像我們如果想只靠背誦記憶學會任何一個專業的專家智慧,也是幾乎不可能的!想當個律師,除了必須熟讀法條之外,更難的是如何分析法律事件的事實與法律之間的關係,法律是比較明確固定的資訊,事實案例呢?即使你有超級電腦的算力與無限的記憶空間,日新月異環境變化產生的新事實還是會讓「只憑經驗」辦事的律師顯得很笨的!邏輯思考能力還是成為專家最重要的基礎。
簡單說,當面對需要解決的問題太複雜,已發生過的事實資料又不足以完整呈現所有可能性時,我們需要的AI就不可能只靠資料的統計與訓練得到!此時準確、精密且合理的邏輯推理才是產出可靠AI的合理方法!即使機器學習確實也可以得到一樣準確的結果,使用邏輯推理的方式建立一樣目的的AI也會更有優勢!
因為你的AI主軸是重現人腦思考的過程,只要能用科學原理準確的理解分析事實,有足夠的數學與程式能力寫成AI軟體,你不需要大量的資料,取得資料與統計訓練的成本就會很低!而且因為你的AI核心基礎是可以準確驗證的科學程序,是具體可見可逐行測試檢驗修改的程式碼,所以你的系統可以不斷在既有基礎上穩定地優化調整,你的AI能力只會進步不會退步!
反之,如果你的AI基礎核心是統計訓練的模型呢?那就表示你的研究其實已經失控了!因為你根本無法掌握訓練完成的黑盒子會根據甚麼程序?會按照甚麼邏輯做出判斷?你唯一能做的「研究工作」只是在你無法控制的黑盒子外繼續找更多資料讓它學習,或是發現它的表現實在太離譜,脫離常識範圍時,強加干涉修改AI做出的判斷!所謂的監督式學習就是那種AI尷尬的遮羞布了!
所以大家必須知道:AI其實有兩種,一種是根據邏輯推理,一種是根據經驗!前者稱之為專家系統的AI,後者就是大家現在比較常聽到的ML、DL與CNN了!前者比後者更早出現,也沒有過時!甚至成本較低精準度更高!但是科學畢竟還有很多未知的領域,當我們對資料因為無知或數量太大無法掌握時,後者以統計學為基礎的AI就管了大用!
所以在此提醒大家AI絕對不只是一種技術、一種方法或是一條道路!事實就不是那樣的!既有使用中的AI其實大部分都還是依賴專家系統,遠多於機器學習等技術,只是因為機器學習近年明顯解決了一些前面數十年專家系統卡關的問題,被大家高度重視而已!光靠他們建構未來的AI是絕對不夠,也絕對不可行的!
尤其是我熟悉的影像辨識領域,我常說統計學靠資料經驗歸納的AI是橫柴入灶!我很確定使用專家系統邏輯推理分析的AI才是正途!才應該是影像辨識的技術主流!我自己就一直以這種方式方向持續研發出很多高效能且低成本的好產品!反觀使用統計AI(ML、DL與CNN)的業者都過得非常掙扎!花很多錢買資料買昂貴的GPU電腦作研發,卻始終做不出夠高辨識率的穩定產品!
在學術界通常只看到某些技術的理論可行性!只要是新的技術且可能有用就會被吹捧!但是業界的AI業者必須真的做出可用的AI產品,如果做不出大家能接受的高辨識率產品,或是開發成本高到公司不堪負荷,或是價格高到使用者買不起,都會讓AI難產!目前影像辨識的業界實況就是這樣!迷信AI就只是機器學習的廠商都苦不堪言!渾然忘了另一條傳統之路的大門始終是敞開的!













限會員,要發表迴響,請先登入


