
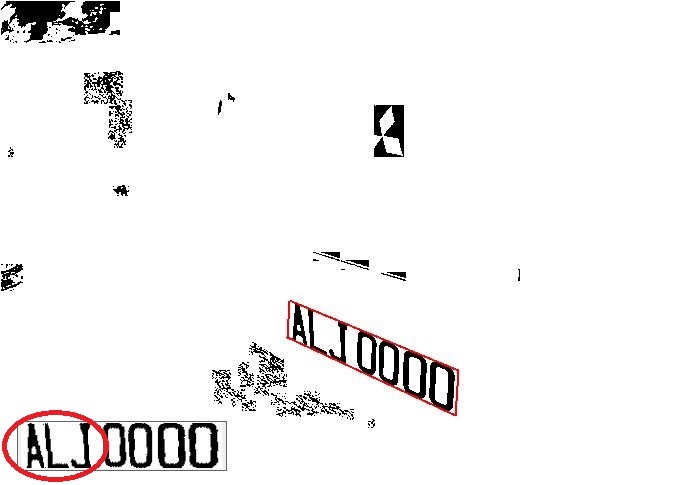
如上的一個清晰車牌的影像,只是略為傾斜了23度,其實就可以難倒大部分以CNN模式的矩形假設搜尋車牌的大部分市售車牌辨識系統了!但是對我們公司的辨識核心來說這只是小菜一碟!那我們是如何克服這些傾斜變形的呢?首先最大的差異就是我們使用了OCR的技術先找到了車牌的個別字元,直接超車了CNN演算法搜尋特徵的繁雜卷積運算前處理,所以我們不需要買輝達的晶片辨識速度就很快了!如下圖:
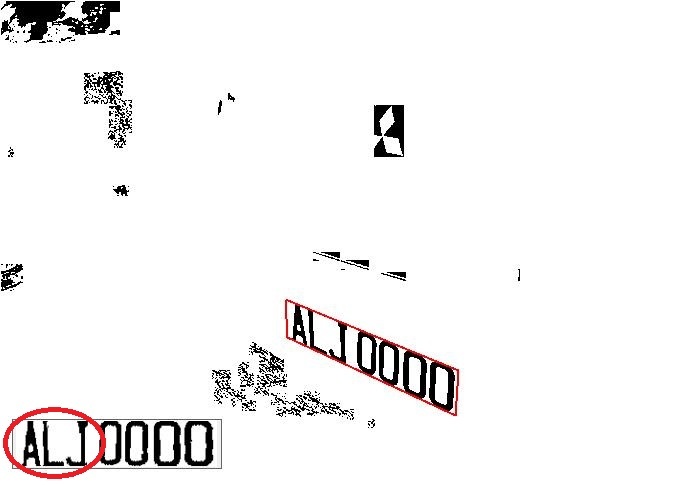
很顯然的,車牌在此影像中不是一個標準的矩形,我們必須設法對車牌字元的群組做幾何校正,讓它們從歪斜扭曲的狀態,變成從前方正視時應有的端正樣貌!這就是我能夠辨識歪斜變形車牌的關鍵處理過程了!但是即使我讀遍所有的車牌辨識論文,加上CNN相關此議題的文獻,都看不到他們對此有何著墨?
我是個受過良好學術研究訓練的台大博士與私立大學資深教授,別看我現在有點像口無遮攔的網紅?就以為我忘了面對科學研究應有的嚴謹態度,我跟一般頂大教授一樣,對於自己研究的議題絕對不會忽略相關學術資訊,只參考膚淺浮誇的網路訊息的。只是我比那些頂大教授更聰明更有創意,也懶得寫論文而已!
在我看過的論文中最了不起的幾何處理就僅止於:平移、旋轉與縮放而已!但是如上的影像即使你把車牌部分轉成水平,字元還是歪的!全部倒向左邊,還一邊大一邊小,距離可以用標準字模去比對辨識是甚麼字還差得好遠!簡單說,只用平移、縮放與旋轉,怎麼操作都不可能讓車牌中的每一個字元都轉正的!如果是來自掃描的影像,如考卷或證件,確實只需要平移、縮放與旋轉就能做到完美的幾何校正,但是來自立體世界拍攝的「平面」車牌呢?扭曲型態就大不同了!

所以要達到辨識歪斜變形車牌的目的,研究出可以將立體世界中拍出的平面影像產生的扭曲轉正的演算法,就是必要的關鍵!我的邏輯是找到車牌字元區的上下左右四條最合理的邊緣切線,有點像任意變形處理的逆運算,玩過PhotoShop軟體的人可能就知道,經過任意變形的手動調整,如上的車牌是可以轉正的!

上圖就是我用PotoShop任意變形的功能盡量扭正車牌影像的結果,如果車牌被處理到這個程度,每家車牌辨識核心都可以正確辨識了!我需要做的就是用自動化的程式做到同樣的這件事!我也做到了,所以我的辨識核心才會那麼強,甚麼角度變形幾乎都能辨識,少了這個程序我的車牌辨識就跟其他廠商一樣只能辨識傾斜15度以下的車牌了!當然也早就混不下去改行了!
其實這並不困難,就是不管形狀是如何扭曲的任意四邊形,四個邊界都做出很多等分點並和對邊的對應點連線,譬如上下邊界之間切出50條橫線線,左右邊界之間切出200條直線,再將這些連線的交點處的畫素資訊投影到寬200高50的一個近似車牌寬高比例的矩形就好了!3D動畫的變形處理都是使用類似的網格演算邏輯的!我只是做更簡化的逆運算而已。

最困難的部分其實是如何總是可以切出正確的四條切線?上下切線大致上就是各字元最高點與最低點的連線,除非字元模糊缺損不然不會太難,找出與所有字元目標頂點或底點偏差最小的直線即可。但是合理的左右邊切線呢?就是更大的問題了!理論上應該是與最左右邊緣字元的「中軸線」同角度的平行線。
但是因為英數字字元並不都是方方正正的國字,在我們只知道某目標是個字元,還不確定是什麼字時,要算出該字正確的中軸線傾角其實是不可能的!譬如A與L都是上窄下寬的字元,碰到L字只要用字元左邊的切線為車牌的左切線,答案就對了!但是碰到A字時也用左邊切線為車牌左切線呢?就會變成這樣了:
這樣去比對標準字模當然會A不像A,L也不像L了,誤認他們是另一個字元的可能性就提高了!我們是如何解決這個問題的?已經研究了很多年,也不是一個簡單的演算公式就可以在所有狀況都適用的!在此先保留一下,或許我的RD可以用這個題目寫博士論文的!
以上的講法都只是點到為止,讓大家一窺我的演算法世界的一些有趣而且人性化的一面!事實上要按此概念實作到面面俱到,絕對是像我們一樣,要磨很多年的!連上面說的上下切線要永遠切得合理,都有很多細節與例外狀況需要處理,真的把四條線的故事說到完整就是一篇博士論文了!還是可以得獎的等級!用機器學習再學多少年都學不到的!
我會想寫這些很可能洩漏太多商業機密的文章,我的樂趣是來自讓更多人體會到AI影像辨識是多麼直覺而且有趣的學問。當然也希望潑一潑那些炒作假AI影像辨識的詐騙集團的冷水!整天吹捧ML、DL、CNN、YOLO、OpenCV或Python的人,多半只是影像辨識領域的騙子或半吊子,我這種真正有做出實績成果的研究者如果不吭聲說點真話,被騙的人就會更多更慘了!






限會員,要發表迴響,請先登入


