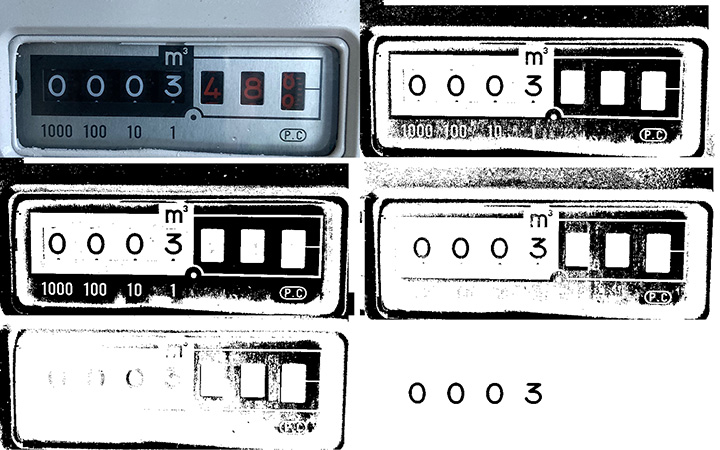
真的做過OCR影像辨識的人,就會知道二值化是很重要也很困難的關鍵步驟!整張圖用同一個亮度門檻是絕對不行的!即使你用了隨著區域亮度動態調整門檻的演算法,也還是有多種門檻決策的選擇,如上就是多種二值化策略處理後得到的不同結果。
如果是前景與背景的對比度很高的字元目標,各種門檻策略,不論是偏高或偏低,結果都會很好。但是偏亮反光的字元,或位於陰影的昏暗字元, 就常常只會在某種二值化策略下才能切割得很好!以上例來說就是使門檻亮度偏低的策略效果較好,偏高時字元就很模糊了!
但是我們其實很難事先決定哪一種二值化策略會得到最佳結果?也不存在某一種策略可以適用於所有狀況,所以只要時間壓力許可,我的影像辨識基本上是每一種策略都試試看的!如果某策略很不洽當,就會找不到合理目標,其實處理程序也會提前收工,如上用四種策略耗時不會是四倍,通常只是加倍而已。
一般OCR的標準程序是:灰階→二值化→定義目標→字元辨識。如果我只有一種二值化策略,很多偏亮或偏暗或比較破碎的字元,辨識就會很容易失敗或錯誤了!所以事實上我的大部分辨識核心都是採用三到四種二值化高低門檻策略的!所以即使只是一個影像,如上的辨識程序我也會做三四次的!
每次不同二值化門檻的辨識,都會有自己的答案!清晰影像時每個答案都會一樣,較模糊時就不一定了!我們會以各個答案的字元符合度與合理性決定哪個答案出線!所以天下沒有白吃的午餐,也沒有萬靈丹!我做的影像辨識軟體好像特別厲害?其實沒有神奇的AI演算法,只是比較努力多嘗試不同辨識略而已。

但是我的軟體速度怎麼沒有因為重複類似程序好幾次而變得很慢呢?如上圖的辨識居然只用掉43個毫秒?真的比眨眼還快好幾倍!原因很容易理解,就是盡量資源回收重複使用雷同的資訊,四次的辨識流程中有很多重複資訊不要每次都重新計算就好了!
這讓我想起小時候我家有年齡各差一歲的三兄弟,小孩子長得快,三年級的制服皮鞋到四年級就不好穿了!但是衣服鞋子不會那麼快就壞掉,穿個三年應該沒問題的,所以通常都可以讓三兄弟穿同一件制服同一雙皮鞋讀「他們各自的X年級」!這樣家裡養三個小孩的花費就不會是整整三倍了!
其實我寫的程式只有我知道是怎麼回事,最多只有我的徒弟看得懂!我要故弄玄虛也很容易的!但是我的老師魂,以及對於AI詐騙集團的厭惡感,讓我總是願意很人性化的介紹「我的AI」!希望可以建立更多後進們的信心!只要相信自己,相信常識,相信直覺,你也可以跟我一樣做出很多好AI的!











限會員,要發表迴響,請先登入


