
第1章 影像辨識簡介
1-1 我認為的影像辨識是…
影像辨識最簡單的定義就是:「從影像中找到我們需要的資訊」!由於多數動物都很依賴視覺提供周遭環境的資訊,經過幾億年的演化,在人腦中已「內建」有非常智慧高效率的影像辨識「演算法」,隨時都在我們的大腦中運作!目前所有的影像辨識專家都還無法完全理解分析這些演算法的邏輯過程,如果可以,我們就能寫出跟人類的視覺能力完全一樣的影像辨識軟體了!
在個人的理念上,影像辨識應該是對於人腦視覺演算法的一個逆向工程!事實上較早期的影像科學研究也多以人眼及大腦為師,很多有關顏色亮度的數學模式都以人眼的感知程度為依歸,譬如明度、彩度與亮度等等。但是當我們開始使用電子元件取得數位化影像時,RGB三原色就變成資料型態的主流,也讓影像辨識的研究慢慢偏離以人腦視覺為師的方向。
我認為,即使人類在近幾百年的科學研究上有很好的成就,可以運用很多數學方法,做出類似人類視覺判斷的影像辨識結果。但是面對來自自然環境中的影像,我不覺得以純數學角度研究所得的影像辨識演算法,其辨識能力與效率,可以超越數億年演化形成的生物視覺演算法!
所以,個人從在學界從事影像辨識研究開始,到創業開設影像辨識專業公司多年,成功研發出非常多種影像辨識產品,辨識能力與速度效能也獲得好評,基本上都是來自盡量模仿人的視覺認知過程,自行設計對應的演算法所得到的成果。
但與此同時,目前影像辨識的主流技術方向已偏向機器學習與深度學習,就是相信以數學或統計方式可以製作出等同,或超越人眼視覺能力的影像辨識軟體!其理念就是相信:從人類數百年來發明的數學方法組合之中,應該可以讓電腦自行學習並「演化」出超越數億年生物演化出來的視覺演算法!
目前機器學習或深度學習宣稱的目標尚未達成,個人也悲觀預期:放棄對於基礎科學的研究,寄望電腦的自行演化可以達到(或超越)人類智慧的程度,是不切實際的想法。所以包括本書在內,我的所有研發產品都未曾使用過任何機器學習或深度學習的方法與概念。對於不知而行的嘗試錯誤研究方式,我們會避免使用。
我想證明的是:基於模仿人眼視覺認知過程設計演算法,就可以完成大多數影像辨識應用軟體的研發製作。根據已知事實,可理解實驗的數據,建立出明確的演算法其實才是傳統科學的精神。事實上也一定會比寄望於以嘗試錯誤為基礎的機器學習或深度學習,更快達到高辨識率,讓影像辨識的應用普及於各個事業領域的目標!相信很快大家就會看到這個必然的趨勢。
簡單說,本書完全不會有機器學習或深度學習的相關內容,也與OpenCV等影像辨識工具無關。只會包含傳統的影像辨識方法實作,以及個人模擬視覺過程設計的一些演算法。只要熟悉C#或VB程式,加上具有高中程度的數學能力,就可以輕鬆閱讀本書,學會實作一般難度的影像辨識。
1-2 影像辨識的過程—以車牌辨識為例
如前所述,影像辨識就是從影像中獲得我們所需要的資訊,如下照片中,有車子、浪板、收費機、與斑駁的路面。但我們想辨識出來的,只是其中的一個車牌號碼!如何用數學方法寫成程式逐步完成資料擷取的工作,讓電腦依照程式的指示運作,最終得到「EZ-5928」這個文字模式的答案,就是影像辨識必須完成的工作。

EZ-5928這個字串之所以對我們產生意義,是因為我們腦袋中已經有這些字元的模型與其所代表的文字意義。我們其實是以大腦中既有的認知,去比對影像中有沒有符合這些資訊特性的目標?如果事實也符合我們比對的結果,就是「辨識成功」了!
1-3 簡化影像
但是我們要找的目標只是原始影像中的一小部分,任何生物的眼睛,包括我們現在使用的攝影機,在取得影像之前都不確定要看的目標在哪裡?特性如何?甚至沒有預期要看甚麼東西!所以都是以自身俱備的感光能力盡量收集最多的資訊。因此,原始影像通常都是資訊過量的,我們作影像辨識最困難的其實就是簡化影像資訊。
人眼通常都能很快在視野中找到我們想找的目標,但是誰都說不清楚詳細的過程,為什麼明明影像中的東西那麼多,我們卻馬上就能盯上那個車牌?這就是數位影像辨識研究的重點了!我們必須設計出簡化資訊,聚焦於目標的演算法,還要節省運算量讓它們很快完成,如果電腦找到車牌的時間比人還慢,影像辨識產品就GG了!
在此,我們是遵照比較傳統的影像辨識流程進行的。首先是從RGB三原色中選取一種對於辨識預期目標最有利的灰階亮度,譬如自然光中綠光對於整體亮度的代表性最高,所以一般車牌辨識可以直接選擇綠光,拋棄紅與藍光來做辨識,也可以計算出RGB的整體亮度,總之就是將RGB三個陣列,簡化成一個陣列作為後續運算的基礎。

因為在此例中我們要找的是字元,特性是獨立塊狀的目標,所以接下來是進一步簡化影像成為黑白圖,希望要找的字元可以被獨立切割出來,字元是全黑的,字元背景是全白的,這就是所謂的二值化過程。

再來是畫出它們的輪廓線,以驗證這些黑色塊狀目標的大小形狀像不像我們要找的字元目標?就是用演算法找出所有封閉曲線,曲線範圍太大或太小的就忽略掉的意思。這好像很複雜?但不必擔心,只要有適當的演算法,就可以像吹掉灰塵一樣,很快清理出可能的目標。

在此必須強調的是:簡化資訊的過程不是可以輕易封裝固定的!每一個簡化程序都會影響到能否成功辨識到我們需要的目標,必須有針對性的設計,譬如用綠光做辨識時,會造成綠色車牌的工程車辨識較差,綠光用在地磅站的車牌辨識系統就會變成劣質產品,改成紅光辨識就會特別靈敏準確,但是碰到紅字的計程車又看不清楚了!
多數影像辨識初學者都很害怕這一階段涉及的複雜條件與數學,寄望有神奇的黑盒子可以直接提供篩選後的合格目標,也因此會有CNN之類的演算模組興起,但是我認為如果想做出針對特定目標最佳化的辨識產品,就絕對不能過度依賴這類演算模組!其實也不會有任何模組可以提供適合所有辨識目的的資訊簡化結果。
想像一下,我們用眼睛找東西時是不是也會有「預設立場」?因為這樣才會有效率!找計程車時,你會注意到眼前黑色的賓士車嗎?一定是對黃色的大目標才有反應!找不同的目標當然會有不同的過濾器,即使你用CNN這類模組,也必須正確且精確的操控它,才會有最好的效率。在我來說,用CNN就不如自己直接根據需要設計了!一定會更簡單有效。
1-4 正規化目標影像
當人眼在辨識字元的時候,就是拿大腦中記得的字型去比對,所以我們寫程式時也一定會先建立這種資訊。就是字型的資料庫,裡面會有每一個字的標準大小圖形。但是我們從原始影像中找到的「可能」是字元的目標,不會剛好與我們事先建立好的字模圖形一樣大,還可能會有傾斜與變形。所以必須有個正規化的過程,以車牌辨識來說,就是將從原圖切割出來的車牌影像,經過幾何計算縮放變形到與標準的車牌模型一樣!

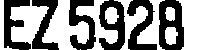
這一部份其實就是要找出原圖中車牌目標區的四邊切線,因為我們知道真正的實體車牌是矩形的,雖然在立體空間中攝得的車牌影像會因為拍攝角度而變形,只要將此任意四邊形投影到直角水平的矩形即可。要理解這部分的演算法,需要一些高中幾何學的基礎,也是本書中最深奧的數學概念了!我會證明作影像辨識不需要懂太深奧的數學。
1-5 字模比對確認資料
完成上述步驟,接下來就可以用個別的字元模型去比對出車牌內容是哪幾個字了!一旦確認是哪一個字,影像資訊就正式變成文字資訊了!以車牌辨識來說,就是達成了影像辨識的目的,這些文字資訊就可以與車牌的資料庫比對,做很多的後續應用。譬如確認為可以開柵欄通行的白名單,或必須攔截查緝的黑名單等等。
一般來說,這部分已經是柳暗花明之後最輕鬆的工作了!所以在整個流程中「找字」是主要的難事,「認字」則是簡單的收尾工作。但是通常此時還必須引進很多影像之外的資訊與邊界條件,對於你找出的答案做檢驗。譬如在台灣不會有「EZ-592B」這種車牌,考量真實世界的物理或法規限制,你可以直接認定那個B是8的誤認,將答案改成「EZ-5928」。
所以我常說:「影像辨識不只是辨識影像!」因為我們的目的是辨識出合理有意義的答案供使用者應用,通常被辨識的目標都會受到一些既定的規則限制,當辨識結果與這些非影像的條件衝突時,我們必須用程式做合理的評估判斷,甚至修改!這不是作弊!因為那些規則比經過拍攝過程被扭曲改變的影像更「真實」!如果你堅持「EZ-592B」的「誠實」辨識結果,其實才是違背辨識目的的決定。
1-6 目標辨識只是影像辨識的一種
以上的影像辨識程序基本上是遵循傳統OCR(Optical Character Recognition),也就是光學字元辨識的程序,它們通常是指文件影像上的字元辨識,但車牌也是字元組成,算是廣義OCR的一種。那是不是所有的影像辨識都必須照這個程序進行呢?絕對不是的!譬如指紋辨識就不行!

切割出上圖中曲折交錯的線狀目標,對於辨識是誰的指紋幫助不大?因為肉是軟的,那些線條很容易會在壓指紋時略微移位,差一點點就會對不上模型影像了!通常的作法是找出這些線條的分岔點,然後依據這些點的分布型態做分類,建立個人的特徵值,作為最後目標比對的依據。所以資訊簡化的方向就不是找到塊狀的目標,也不是線狀目標,而是分岔點!使用的程序當然會不同!
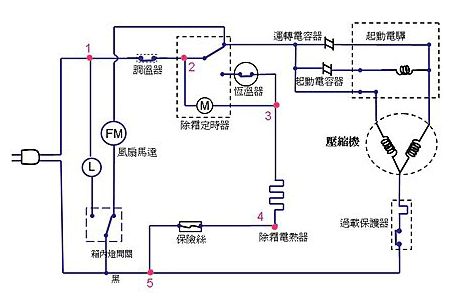
又如上面的電路圖,如果要辨識出其中的電子元件,因為全圖元件都是相連的,你根本無法以OCR的概念切出獨立的元件目標!必須發展出其他的辨識程序才能抽離元件。所以影像辨識的流程都不會是完全通用的!必須依據目標特性與辨識目的做針對性的設計,本書限於篇幅,只會介紹以OCR為基礎的「一種」最常見程序,但影像辨識的博大精深學問絕對不止於此!







限會員,要發表迴響,請先登入
 1樓. 大隻熊2021/09/03 16:25我也覺得用統計學做AI並不適合~~
1樓. 大隻熊2021/09/03 16:25我也覺得用統計學做AI並不適合~~


