車牌辨識也可以追蹤殘缺證據與蛛絲馬跡來破案的!
2025/10/16 16:24
瀏覽556
迴響0
推薦5
引用0

現在每天都在一大堆之前辨識失敗的困難影像中奮戰,很像我愛看的警匪偵探影集,我就是那些對於尚未偵破抓到兇手的懸案緊追不捨,數十年都不肯放手的死腦筋偵探了!如上的案例就是人眼視覺上似乎可以辨識?但是經過數位化的資料處理,字元目標都是破碎不完整的!
如何盡量合理的利用這些破碎的蛛絲馬跡重組出最接近合理正確的車牌?這是一個可以研究不完的有趣議題,也讓我手上幾批數千張的影像辨識率從幾年前的五六十趴,到現在的八九十趴!這些資料都是早期客戶回饋的辨識錯誤的資料哦!也就說我的起跑點是0%!如果與一般正常的影像一起算,我已經是在很極端的百分之一二的困難尖端做研究了!而且我每天都會偵破好多個懸案!順手在FB上分享一下這些精采案例就更好玩了!

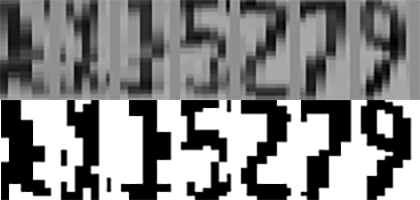
看到上面這些將支離破碎的目標重組成車牌字元的過程圖,你就會知道我的車牌辨識研究是很精緻穩定踏實的科學實驗過程!很微妙的是,到了最後要判斷破碎模糊的目標是甚麼字的時候,還蠻像機器學習(ML)或類神經網路(CNN)的!
每個模糊目標與每個標準字模的相似程度都必須有精準合理的量化評分!如上的A、X與J三個字跟清晰標準的字模當然相差很多!但重點是我的評分方式,也就是如類神經網路的相似度加權方式,必須能模擬人類的視覺判斷!我的程式與人眼的判斷必須盡量相同,那個A雖然很不像A,但是也不會更像任何一個其他的英文字母,那它就應該是A了!這就是「AI」,就是「人工智慧」了!我們的腦袋就是會這樣判斷的嘛!
所以你能說我不用機器學習、深度學習與類神經網路就不是AI了嗎?我其實是用比那些所謂的AI演算法,更可靠更合理與更穩定的演算法,來推進AI目標的務實研究者!我的神奇辨識結果的背後都是點點滴滴的辛勤研究得來的!絕非欺騙也毫無僥倖!








你可能會有興趣的文章:
限會員,要發表迴響,請先登入


