

這種因為車燈太亮而變得很難辨識的車牌照片,在我的新版技術下成功率大幅提升!原因很有趣!如上圖大家可以看到我的OCR辨識程序在原圖中其實無法正確切割出那個邊緣的5字,但是我在抓到比較確定的ASL-657等目標之後,有意識的略為擴大處理區,左右都多取了一小塊區域進入幾何校正的程序!
所以幾何校正出來的二值化車牌影像左右邊都多出一個小區域,如果因為任何原因我的OCR漏掉了邊緣的字,就不會完全被遺漏排除在最終的答案之外了!這其實是很常發生的事情,除了上面的車燈炫光之外,台灣的六碼車牌邊緣字與車牌邊界空隙極小,稍微一點模糊的狀況就會使邊緣字與整個背景沾連,我在原圖中就切割不出那個字了!
我之前的做法是在原圖中嘗試用CNN的方式去搜尋硬挖出可能遺失的邊緣字,但是如前文說,因為原圖中的車牌可能是歪斜的,用不歪斜的標準字模去找歪斜的答案常常是不準確的!如果我讓這些可能有遺失字元的區域跟著可靠的目標區一起接受幾何校正呢?
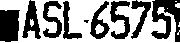
從上圖中我就可以用CNN的方式掃描左右多出的區塊,如果那空間中有遺漏的字元也會被修正到不歪斜的狀況,我就可以很快很正確的找到遺珠了!以此例來說,左邊的黑方塊當然不會像任何英數字,但是右邊的那塊就很容易看出來是個5字了!
這就是考試備取的概念了!要給還在及格邊緣以下的考生一些機會,筆試或許不及格,但是口試時可能會證明他很棒!而且對於車牌辨識來說,少任何一個字就是完全錯誤的答案,所以如何避免遺珠絕對是非常重要的程序!
從此各位也可以知道我的辨識軟體正確率高,速度又快,絕非僥倖!好的辨識軟體不但要保證找到所有的目標,還必須很快!絕對不能只依靠機器自己去摸索學習的!要讓任何電腦從大量資料學會如此精巧的智慧處理程序太難了!即使真的可能做到,需要的成本與時間也會太高的!
我只想告訴大家:我的這條AI影像辨識之路不但走得通,效率也比使用ML、DL與CNN高很多很多!機器學習與深度學習其實只是提出了一個夢想與願景,在資料量大到人腦很難記憶兼顧的議題上表現確實會優於人腦,像是下棋!但是說到像影像辨識這種需要精密準確與抽象複雜程序思考的智慧呢?我們有生之年都不會看到的!別痴痴的等了!你沒這麼長命的!










限會員,要發表迴響,請先登入


