
任何認真做過影像辨識的人應該都會覺得這個辨識結果很誇張!根本是作弊後製造假的吧?但這確實是真的!我的「AI」車牌辨識軟體就是照著它內定的SOP跑出這樣的結果!如果你想用機器學習(ML)與類神經網路(CNN)的方式「訓練」出這種辨識能力?那才是天方夜譚,絕對不可能的!
如果那麼黯淡的7、8與C字元都要程式做出發現「有特徵」的反應,那需要處理的雜訊資料量就太多了,絕對會讓CNN的運算量暴增到崩潰的!這麼奇怪特殊的案例如果也要機器學習到會的話,ML需要的資料量與訓練時間也會讓你的公司徹底被拖垮倒閉,再多的錢、設備與時間投資下去都沒用的!
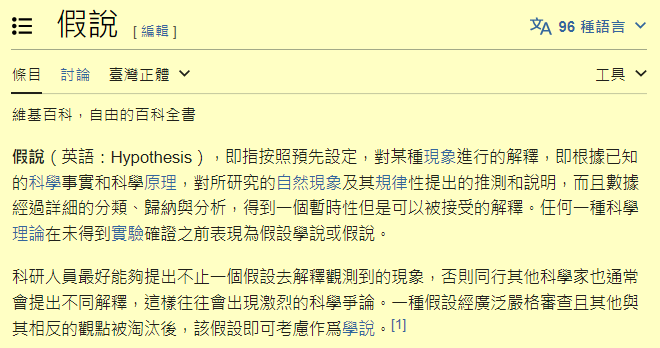
那我是怎麼作到的呢?其實一點都不神奇,就是幾百年來的正統科學家一直都在用的方法概念!請大家仔細看下面這段維基百科節錄下來的文字說明:
ML與CNN的概念是相信我們需要的所有資訊都在資料(Data)之中,只要資料夠多夠完整,終究是可以用各種數學模式「學會」的!機器學習不夠就「深度」學習嘛(DL)!喝酒不夠嗨就吸毒嘛!理論上好像沒錯,但是實務上要執行就很容易變成災難了!他們可能沒注意到:對於較抽象的問題來說,用電腦根據資料學習的成本比使用傳統科學研究方法解題昂貴太多了!
關鍵差別就是如上的「假說(Hypothesis)」概念!數百年來的傳統與正統科學一直都不是用大量的資料統計來找到正確答案的!科學家都是先觀察到確定的自然現象,根據少數已知的確定資訊開始建立假說,然後依循假說繼續找可以證實或推翻或修正假說的新證據,逐步聚焦到正確學說的!
這是很必要的正確做法!電腦發明之前我們根本不可能沒事就來「遍歷」所有已知資料一下,圖書館的書都讀一遍一輩子就過完了!那科學的進展會多慢啊?所以科學家會很精準地根據假說,去找到可以證明或推翻假說的關鍵資料,或針對目標做精確實驗釐清關鍵疑點!證實假說正確就繼續挺進,有錯誤就修正假說!絕對不會以不斷反芻大量資料為工作重心的!
我的影像辨識就是這樣做的!以這個案例來說,我根據監理單位公布的車牌規則建立了假說,先用比較簡單的OCR辨識程序找到明顯的目標,但我只能辨識出DW 00等四個字元,不完全符合我的假說,我就根據假說的架構,到「可能」缺字的位置作更徹底的搜尋,那些黯淡的字元如果不是剛好在應該有字的位置,我根本不會也不需要去找它處理它的!
但是如果在應該有字的位置發現蛛絲馬跡呢?即使資訊已經很模糊,應該也可以判斷那是一個字了!所以我沒有像CNN一樣全圖搜索所有的細微特徵,也不必像機器學習一樣抓瞎讓電腦練習天文數字的大量資料,概略掃描鎖定可能的車牌位置再針對關鍵區域啟動地毯式搜索,很快就可以做出這麼聰明的辨識了!
重點是我使用的成本很低!不需要大量類似資料來做機器學習,也不需要在目標影像中做太多不必要的特徵搜尋!所以我才能不花很多錢就很快推出那麼多執行快速又聰明的影像辨識產品!所以何謂「先進」的AI影像辨識技術?你確定是ML、DL或CNN嗎?我很確定不是!這也很像我的地質老本行,要挖到化石或石油你都必須依賴很多假說的!亂槍打鳥就是所謂的野貓井了,挖井是很燒錢的!很多人都因此傾家蕩產還挖不到一滴油的!








限會員,要發表迴響,請先登入


