經過幾個月的學習,漸漸弄懂很多機器學習的基本概念了!我做的影像辨識題目與目標都跟機器學習性質類似,所以自始我就覺得認真學下去,一定會和我的理念方法有很多相通之處!我已經在這些問題中浸淫研究多年了,不像多數機器學習的初學者腦袋經驗空空,所以我只需要理解那些數學方法對應試圖解決的是我熟知的哪個狀況即可!
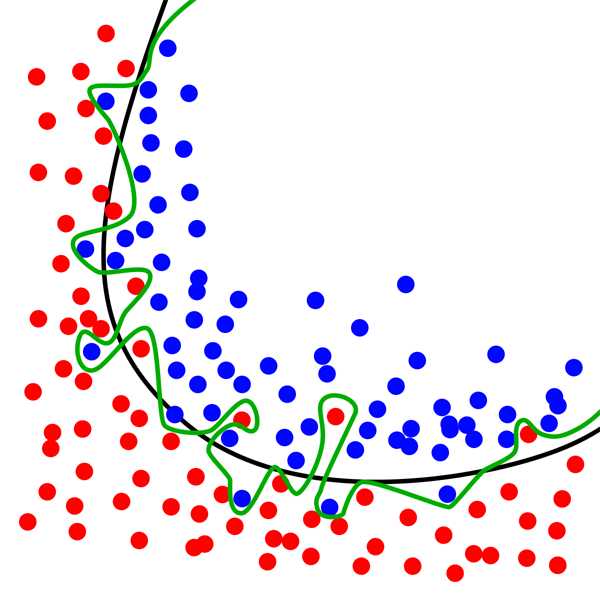
如上圖的狀況,現實世界的資料確實都會在類別邊緣有些混雜,譬如建中的學生不會保證每一個人每次考試成績都會永遠比師大附中的好!你只用簡單的指標想做精確完整的分類是不可能的。我們這種專家的工作,就是試著多用一些資訊或指標作出更準確的分類,也就是努力辨識出每一個目標了!
上圖的概念,是想使用一個函數,在二維的座標平面上將兩種已知種類的目標做分類。有點像以身高體重為分類標準,想正確分辨出體適能及格與不及格的學生!如果完美成功,以後我們只要不擇手段讓學生達到身高體重的那個函數標準,他的體適能測驗就一定會及格了?
事實當然不會那麼簡單,所以在二維平面上可以完美分類測試資料(Trainning data)的綠色複雜曲線(函數)通常無法套用到其他的新資料(Testing data)!我們必須超越這個二維架構來思考才能逼近解決問題的目標。我們可能還要考慮他的體脂肪比例,甚至有無特殊病史?父母親是否喜好運動?等等很多定性而非定量的因素。
可以量化的資訊(屬性),譬如體脂肪就可以變成另一個向量維度,上面的問題就會變成三維空間的數學了!但是實際上需要考慮的相關資訊可能有七八種之多,那就會變成只能用想像力理解的高維空間問題了!至此,數學不是超強的人都已經快被嚇死,玩不下去了!
但是連數學也很強的人都會頭痛的是:無法定量的定性屬性怎麼辦?譬如我們考慮了很多一個學生能否考上建中的原因,所有綜合指標的分析結論都是他一定可以上建中,但結果是他的父母堅持要他出國讀書,一個事件就否定了所有的分類結果!現實世界這是很常見的,在數學上就必須使用所謂的δ function,也就是程式語言中的If…then…else了!數學式子被這麼一攪和就不會很完美優雅了!
其實我自己面對一樣的問題時,絕對不會很快的將方法論提升到高維空間!那是我最後不得已才會用的選項,為什麼?是我數學比較差嗎?不是的!是我的直覺告訴我:買牛刀來殺雞會浪費很多錢的!都還不知道為何簡單低維度的函數不能完美解決問題的原因,就急著搬出更複雜的數學,即使成功也可能會耗費太多無謂的計算時間!
對於軟體設計來說,功能要達到是必然的,但是效能也是必須考慮的!使用較簡單有效的方式解決問題表示計算量少,時間短,不必用太好的電腦,這就是成本了!我們業界人士一定會非常在意,但是對於做學術研究的教授學者們來說,通常是無感的!這跟論文是否會被接受沒有太大的關係!數學架構是否清晰完美才是重點!
所以我(一個業界RD不是教授)的作法一定是先嘗試研究出上圖中少數偏離簡單函數分類的案例,既然是少數的例外,就盡量用例外處理的方式去將他們以類似個案的方式處理,就像全班只有一個人不及格,不必為他加開一門課的,叫他到老師辦公室課後輔導即可。
但是真實使用這個函數(軟體)時,受測資料是沒有標準答案的!所以我必須在計算過程中判斷是否可能出現異常了?我怎麼知道呢?就是要研究那些分類成功與分類錯誤的資料間有何明顯差異了!就像健康與生病的人之間有甚麼可以分辨的徵兆?譬如頭痛等等。出現某些徵兆時我就必須開啟例外處理程序,沒有徵兆時就可以放心用主要的函數(辨識程序)確認答案了!
我的這些設計理念與機器學習說的Overfitting是不太一樣的!Overfitting是指使用數學函數去強制迎合測試資料,過程中是不考慮物理事實現象,只問資料符合度的!我的例外處理則都是依據我對測試例外的個案研究的結果而設計的,如果在我的大量測試中從未出現的狀況,我也不會做出相應(無中生有)的程式,這是我的軟體地雷嗎?可能是,但是機率很低,即使真的發生了,只要客戶將案例回饋給我,我也能立即研究修補好漏洞,問題不大的!
這種處理概念落句英文可以稱之為Smart decision,我目前還完全沒在機器學習理論中看到,預計也不會看到!但是我知道所有實用的AI軟體研發者,必然都會跟我一樣這麼做的!因為對症下藥只寫出必要的程式,才能不浪費運算資源降低成本,而且使用越複雜的數學架構,譬如高維函數空間,就表示日後面對客戶的回饋錯誤案例,你比較難分析解決錯誤的原因,要做好客後服務就累了!












限會員,要發表迴響,請先登入


