
這樣的OCR辨識看起來相當困難,但是如果你用PhotoShop軟體的臨界值功能,用滑鼠拉一拉門檻值,就可以輕易得到一個清晰到不行的結果:
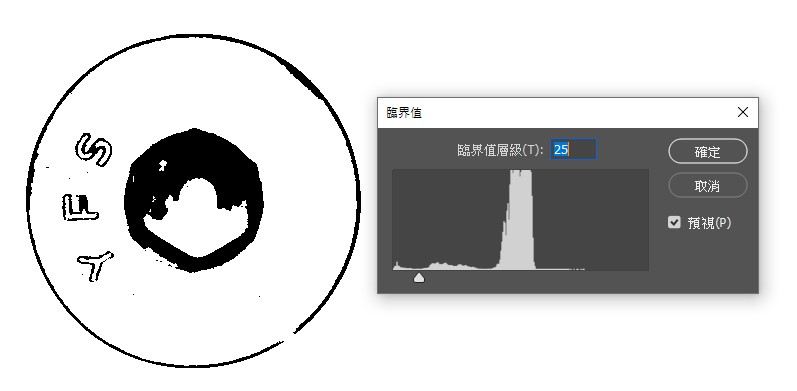
所以我們知道以此例來說,理想的門檻值是確實存在的!問題在於一個自動化判斷的「AI」程式,要如何找出那個理想的門檻值呢?理論上,我們都很希望可以用上圖右方的灰階柱狀分布圖建立出一個邏輯,譬如將門檻值定在兩峰之間的低點等等…。但是實務上變數太多,很難有簡單一致的穩定邏輯,雜訊的強弱與分佈是不會很守規矩的!
我研究如何用數學方法決定出理想門檻值很久了!看過,也用過很多演算法,但沒有一種方法會永遠合用。我當然會尋思:那人是怎麼看出那幾個字元的呢?如果多花一兩秒鐘「仔細看」,視力正常的人還是都能看到那三個英文字母:YFS。
通常第一眼看去一定不會看到有字!那就是我們的腦袋用了一個最簡單的演算法決定黑白兩色的門檻,那個門檻大約是在螺絲釘的平均亮度與灰色的背景亮度之間。於是字元與它緊鄰的背景會通通偏向深色,你就看不出那些「字塊」了!
此時我們應該會將視覺焦點放到較深色的螺絲釘頭內部,再參考那些咖啡色區域內的亮度分佈,決定一個新的門檻值,因為我們預期要辨識的目標一定在螺絲釘頭的內部嘛!此時那幾個字就會開始浮現了!
所以人的視覺應該也是包含了嘗試錯誤運算的!這沒有甚麼不好意思,重點是我們該如何快速地完成這個嘗試錯誤的過程,最好第二次就猜對!看不到目標就換參數,換招式,這跟機器學習的概念也有幾分相似,但如何從前一次的錯誤經驗中盡量中找到有用的參考資訊,不要重複做一樣的計算,所有資訊都要資源回收重複利用,這樣你就可以很快找到答案了!
我的辨識程式就真的是按照這個過程作的!首先用成功機率最大,也最簡單的二值化策略,字元區算是浮現了,但不是很清楚,辨識結果是這樣的:
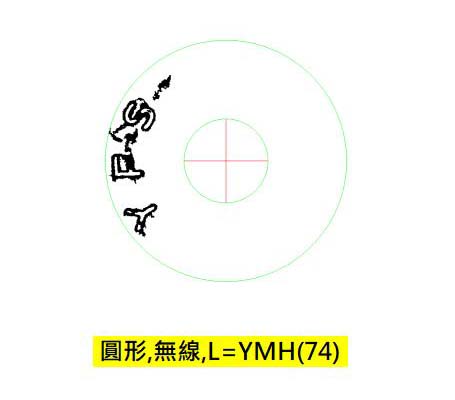
我用一些強制過程辨識,也是會有答案出現的,但會同時得到一些警訊,顯示這個答案可能不太好?譬如字元的大小間距不一致之類的。所以我會調整二值化的策略再做一次!前一次看起來字元好像黑色偏多,有點沾連的跡象,所以第二次我會降低門檻,讓黑區變小一點,或許就可以得到較乾淨的字元了!
果然效果好很多,比對字模的結果相似度大幅提升了!從74到84分,這個答案大概就不會錯了!分數夠高可以收工了!
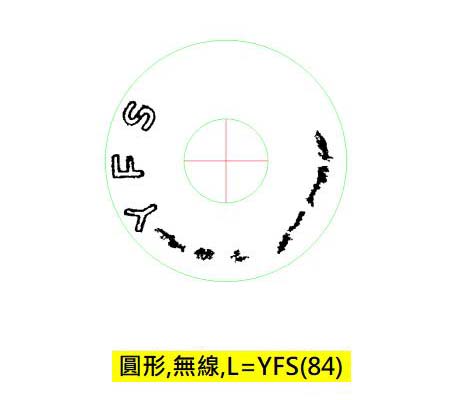
但是大家也可以看到,讓主要字元目標變清楚的策略,也可能會產生新的雜訊!我們也必須嘗試評估辨識這些雜訊,確定他們不是真的有意義字元。就像我們瞇起眼睛看清楚了主要目標,通常也會附帶看到一些新的雜訊!這個過程很有趣的是:我天天罵ML是盲目亂踹,其實我自己好像也差不多?差別是必須有策略有方向的去嘗試下一步!
作影像辨識除了要找到答案,辨識速度也是很重要的!如果你太迷信數學,就是想一次引進所有的變數,作最全面完整的考量計算,一次決定出最佳的二值化門檻,你的計算可能就會很複雜很久。用比較粗略的估計方式則很快就可以雖不中亦不遠矣!
但是你就必須再次作更趨近目標的第二次,甚至第三次二值化!此時減少嘗試錯誤的次數,盡快聚焦到夠好的答案,讓計算可以合理結束,就是辨識速度快不快的關鍵了!重點剛剛說了,就是已經算過的基本資訊要盡量重複使用,還必須從前一次的嘗試中做一些簡單的檢測評估,決定最佳的調整策略方向。






限會員,要發表迴響,請先登入


