從昨天到今天中午,筆者忙了一天半的時間,為 SiaTaigi 設計檔案格式,並在 Menu Bar 新增 Open&Save File 功能,而這個 SiaTaigi 的檔案格式,除了 Header 之外,從 GtkTextBuffer 抓到的 UTF8 Data (Unicode Transformation Format, 8-bits),是經過 zlib API 做完資料壓縮之後才寫入檔案。一邊設計與測試並一邊修改以及增修,終於有個不錯的寫檔與讀檔的版本,還蠻有小小的成就感,沒想到已經將近 20 年沒有什麼在寫程式,但這一天半寫下來,還是寫得津津有味、覺得頗有趣味,更重要的事情是:自己就是使用者,哈哈!來依序看一下 Screen Snapshots。1. Menu Bar 新增 File, File 之下的 Pull Down Menu 有 Open, Save, 以及 Exit。
02. File Type:SiaTaigi
SiaTaigi File 是筆者所設計的檔案格式,其中含有 SiaTaigi File Signature, Header 大小為 64 bytes,而從 GtkTextBuffer 抓到的所有 UTF8 Data,筆者是使用 zlib API 執行完資料壓縮之後才寫到檔案。
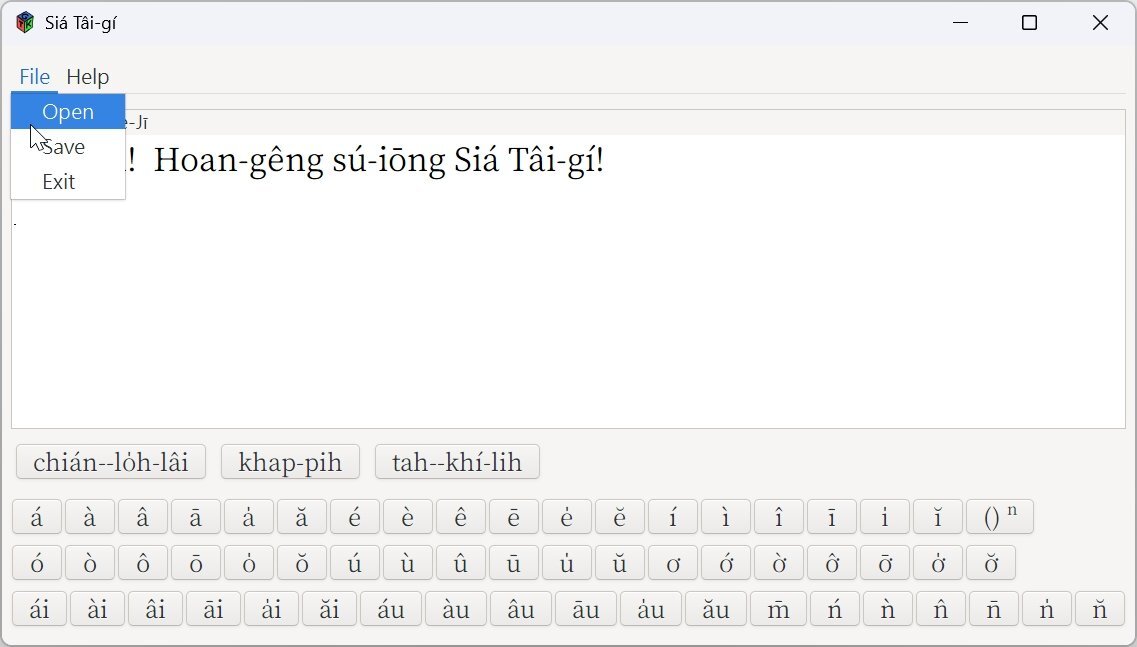
So, 如果使用者開啟一個不是 SiaTaigi 檔案格式的檔案,Open File Dialog 會秀出 Warning Dialog 如下:
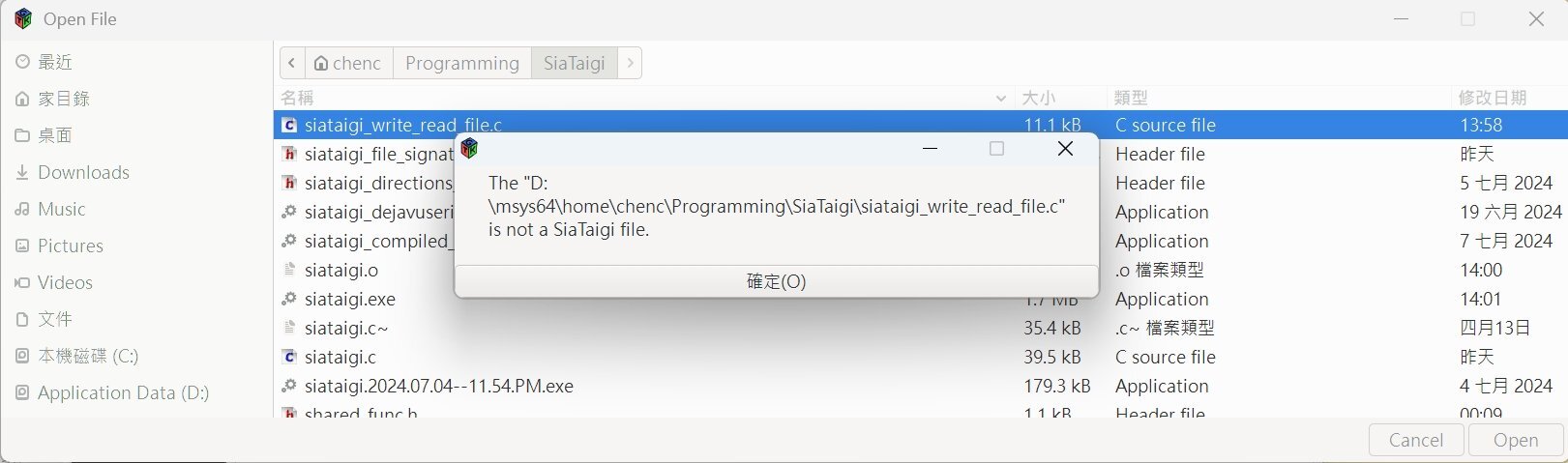
03. 讀一個 SiaTaigi File "test_compressed_05.stg" 的顯示結果
附檔名 .stg 是由 SiaTaiGi 而來,寫檔時的 Write File Dialog 會自動給一個預設的檔名,叫做 "untitled.stg"。
04. 目前總共測試了 10 個檔案;
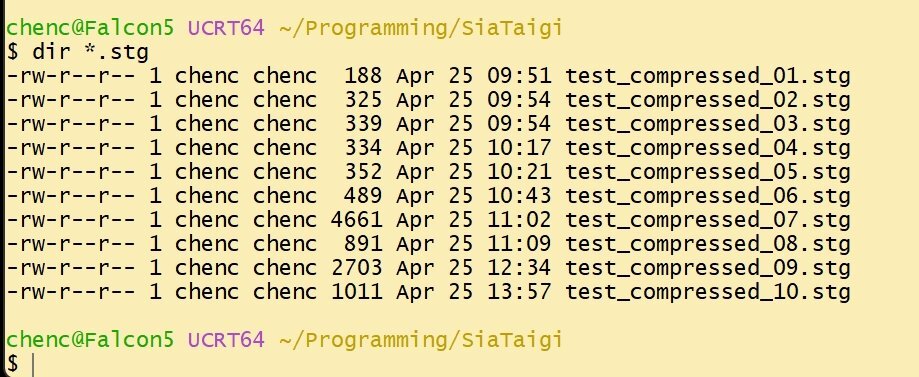
以 test_compressed_05.stg 來說,它的檔案大小為 352 bytes,其中 64 bytes 是 Header,壓縮的資料大小為 288 bytes,解壓縮後的資料大小為 2076 bytes,由此數據可算出 zlib 將原始資料縮小了 7.2 倍。
05. 秀一下 test_compressed_05.stg 的檔案內容;

06. 秀一下創造者所享有的特殊權利:把自己的 POJ 名字編進字典,哈哈!
POJ 的我們 "gún",去掉聲調符號會跟英文字的 gun 衝到,但因為筆者針對 Hashing 的對應保留了「十個位置」,所以空間足夠容納 POJ 的 "gún" 以及英文字義 "gun" 所對應的 "chhèng",到時候再把這對應加入 static array。
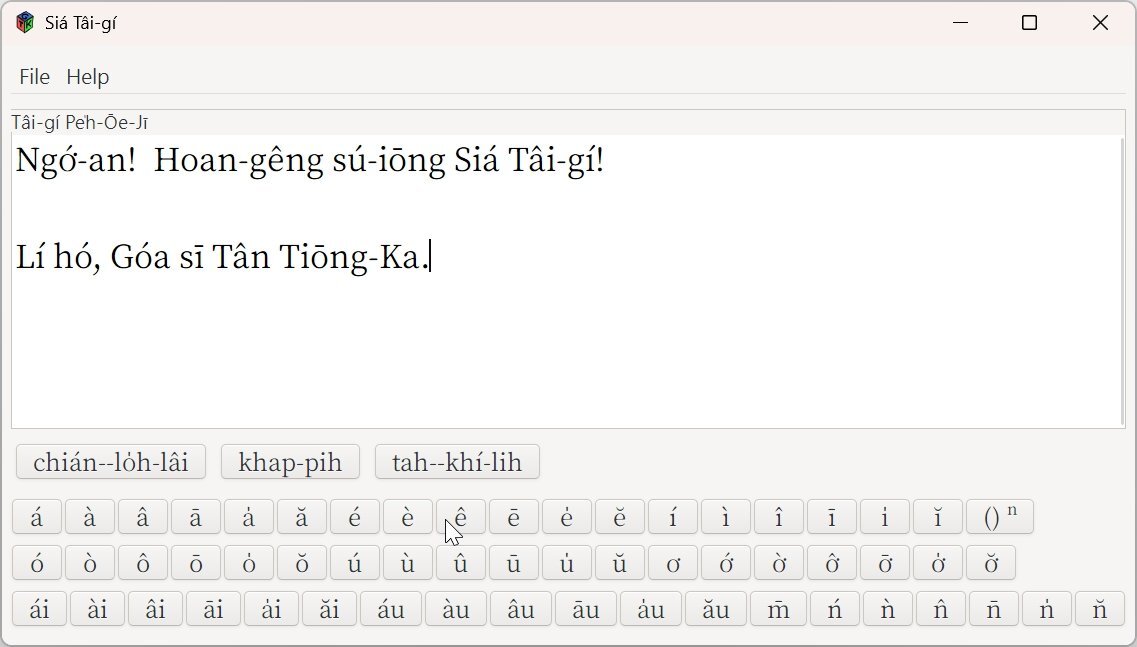
07. 有了字典,書寫台語白話字更方便!
以下列截圖為例,筆者所鍵入的字元順序為:
li-ho (透過 Ctrl+Enter 做字典對應:Hashing --> lí hó --> Lí hó)
,
goa (透過 Ctrl+Enter 做字典對應:Hashing --> góa --> Góa )
si (透過 Ctrl+Enter 做字典對應:Hashing --> sī)
tan-tiong-ka (透過 Ctrl+Enter 做字典對應:Hashing --> Tân Tiōng-Ka)
Wow, 比 SiaTaigi 0.5 版好用多了!
寫到這裡突然想到:gōa 也蠻常遇到的,它的主要字義包含「外面的外」、以及「若干個」等意思,所以也會將它列入 goa 的 Hashing 對應組合裡。
Well, SiaTaigi 沒有做 File Locking,因為筆者在想,這使用者人數很少,大概不會碰到需要做 File Locking 的情況 (這個應用程式在執行寫檔時、另一個應用程式又要讀這個檔)。一般來說,市面上的知名應用軟體,例如 Adobe InDesign, Lightroom 等等,它們會創建另外一個檔案來做 File Locking,但筆者是有點納悶為何需要另外創建一個檔案來做 File Locking,因為 System Call 就已經有 lockf() 以及 fcntl(),而且 fcntl() 還可以控制要從檔案的哪一個 byte offset 開始做 locking,以及 locking length 有多長,What I mean is: lock 自己就可以了,不想 lock 自己全身也可以指定範圍,為什麼還要創建出另外一個檔案來做 locking?相較於 SiaTaigi,筆者任職 EDA 產業時所設計的 FSDB,就是一定要做 File Locking,因為一邊跑 Digital Logic Simulator 來寫出 simulation result、一邊使用 Waveform Viewer 來看 simulation result,是 Digital IC Designer 的工作習慣 (For a Big Design,Simulator 跑 Gate Level Simulation,一次就跑超過一個禮拜是很常見的);除了 File Locking 之外,那 Header Section 的設計也可以有所區分,亦即 Write-Once Data 以及 Non-Write-Once Data 可以分開存放,亦即 Header Section 可以再細分為 Write-Once Section 以及 Non-Write-Once Section,Why does it matter? 因為 Write-Once-Data 不用一寫再寫,而且 File Operation 的速度跟 Memory Operation 的速度相比,至少慢上壹千倍,若是跟傳統的磁性硬碟相比,那速度更是慢上十萬倍 (例如,SSD 100 microseconds / RAM 100 nanoseconds = 1,000.;HD 10 milliseconds / RAM 100 nanoseconds = 100,000.),沒有必要一寫再寫的 Data 卻每次寫,必然降低程式的執行效率,而無謂地移動那 File Position 也是會耗掉許多時間!
BTW,現在多數人所使用的手機之晶片 (SoC) 幾乎都是 Little Endian,精確地說是 ARM 的 Default Endian Type 是使用 Little Endian (ARM 支援 Bi-Endian,可以切換),再加上現在有不少 IC Design House 是大量地使用 Linux 平台在跑 Simulation (例如 Linux Rack Servers),也就是 Endian Type 都是 x86 的 Little Edian,所以 SiaTaigi File 也不需要處理 Byte Ordering 的問題,更何況筆者手邊也沒有 Big Endian 的機器平台可以編譯出該平台的 SiaTaigi 版本,不過 SiaTaigi File Header 裡面仍是有記下執行平台的 Byte Ordering。
至於 Encoding 的部分,UTF8 就已經是一種 Encoding,它已經盡可能地使用最少的 Byte Count 來表達資料,所以也沒有什麼空間再做 Encoding;順道一提的是,MS Windows 全部都是使用 UTF16,它是使用 2 bytes 或 4 bytes,而 UTF8 是使用 1 byte、2 bytes、3 bytes、或是 4 bytes;因此,就英文與台語白話字而言,UTF8 很省空間,而 UTF16 比較浪費空間,而且那浪費沒有使用的空間,是有機會被植入一些不該有的資訊,但如果全部都是中文、日文、以及韓文的資料,則 UTF8 是使用 3 bytes,而 UTF16 是使用 2 bytes,此時就是 UTF16 比較省空間;然而,除了空間的考量之外,對「資料傳輸的部分遺失」或「從不對之處開始讀取資料」的自我驗證與修正能力而言,UTF8 是大勝 UTF16,因為 UTF8 的 Encoding 設計,讓它可以從 Leading Byte 與 Continuation Byte 做自我驗證與修正,但 UTF16 遇到上述問題時是沒有辦法做自我驗證與修正,只要連續遺失的資料量是奇數個 byte(s),或從不對之處開始讀取資料(因為 UTF16 沒有 Leading Byte 與 Continuation Byte 的概念),資料就會從出錯之處隨後整個亂掉!
最後分享一下筆者的 zlib 使用心得:不要使用那 Simple Wrapper,直接使用 Stream-Based API, 亦即:
deflateInit()
deflate()
deflateEnd()
inflateInit()
inflate()
inflateEnd()
至於 zlib 的壓縮效率,以 GtkTextBuffer 為例,它的資料都是 UTF8 格式,若資料量在 128 bytes 以下,透過 zlib 壓縮,壓完幾乎都是變大;若資料量在 128 bytes ~ 256 bytes 之間,則是有時變大、有時變小;若資料量在 512 bytes 以上,幾乎都是變小;當資料超過 1024 bytes,壓縮效率都不錯,UTF8 Data 都可以壓到 5 倍到 10 倍左右。
好了,今天就寫到這裡,Have a nice day!