



論文中先用小實行做出 policy evaluation 測試

是以所有兜起來 就和DQN一樣 只是找max_q 的話不再只是用最後一層的神經元去找 而是採用倒數第二層的神經元算出來的資訊的max去找
The dueling network automatically produces separate estimates of the state value function and advantage function, without any extra supervision.
其實令我最驚豔的是這句話
而且在後面又講了一次


[2] Baird, L.C. Advantage updating. Technical Report WLTR-93-1146翻譯社 Wright-Patterson Air Force Base, 1993.
The estimates V (s; θ, β) and A(s翻譯社 a; θ, α) are computed automatically without any extra supervision or algorithmic modifi- cations.
Dueling Network Architectures for Deep Reinforcement Learning
可以發現綠色的線的確對照快收斂 10個action 代表隨機塞6個 don’t move 進去action space 中 20個也是一樣的事理 由圖可以發現 愈多action space 效果愈光鮮明顯
最後履行這行程式
由上圖對照可以發現 value network 在意的是遠方呈現的車 而advantage network 完全不在乎 可是情況如果換成下面這個 由圖可以很較著發現advantage network 在乎的是四周呈現的車輛而value network 雖然也有觀察到四周的車但是由圖顏色仍然可以比力出來 遠方的橘色局限比力大並且色彩也對照深 說明value network 仍是對照正視遠方車的
Equation (7) is unidentifiable in the sense that given Q we cannot recover V and A uniquely. To see this, add a constant to V (s; θ翻譯社 β) and subtract the same constant from A(s, a; θ翻譯社 α). This constant cancels out resulting in the same Q value. This lack of identifiability is mirrored by poor practical performance when this equation is used directly.
然則後來實行發現 改成下面這個結果也都和上面這個公式差不多 是以作者說此篇論文所做出來的實行都是用下面這個公式
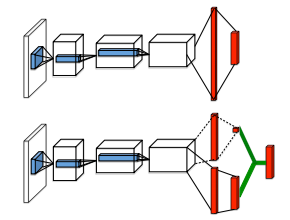
這是他的網路架構
上圖即為原始網路翻譯社下圖為dueling網路 首要的分歧點在於--conv攤平後的神經元 分別分成雙方

居然會主動產生 state value 和 action value 並且還不消supervise 它 的確太奇異!!
action 總共有4個 離別是 上下擺佈 還有一個不動 SE代表square error
這是鉦昱翻譯公司再https://github.com/devsisters/DQN-tensorflow找的程式
這系統就仿佛鉦昱翻譯公司們的人腦一樣 每一塊大腦的功能專注於某一件事 最後大腦要把所有資訊整合做出最後決議計劃 是以我認為這篇paper 又向發現大腦的奧秘更進步一步了 難怪會成為ICML的best paper
這是DeepMind做出與本來DQN的分數對照 每列代表不同的Atari 遊戲 可以看出結果切實其實提拔許多
本篇論文用此圖當例子說明為何要分成兩部分去訓練 左圖代表value network 右圖代表advantage network 橘色的部分代表當前網路注重的範圍 至於若何產生的 論文參考[1]
左圖是一個10個垂直方塊 接50個平行方塊 然後再接10個垂直方塊的 corridor
下面剖析改善體式格局:

論文前面就有提到 這是個把前人的研究功效 [2] 套到DQN上 所構成的一個新的網路架構 這是Baird 再1993做的研究 他證實出advantage updating 確時收斂的比 Q learning快 按照定義我們可以獲得adavantage function 如下
Moreover, it would be wrong to conclude that V (s; θ, β) is a good estimator of the state-value function翻譯社 or likewise that A(s, a; θ, α) provides a reasonable estimate of the advantage function.
[1] Simonyan, K., Vedaldi, A., and Zisserman翻譯社 A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034翻譯社 2013.
然則這會讓我們產生沒法分辯的問題 解決方式以下

To address this issue of identifiability, we can force the advantage function estimator to have zero advantage at the chosen action. That is, we let the last module of the network implement the forward mapping
上面稱為value network 下面為advantage network ,其實講白化一點就是把state vale 和 action value 都斟酌在內
來自: http://darren1231.pixnet.net/blog/post/333559752-dueling-network-architectures-for-deep-reinforcemen有關各國語文翻譯公證的問題歡迎諮詢鉦昱翻譯公司02-23690937
限會員,要發表迴響,請先登入


