第5章死結(Deadlock)
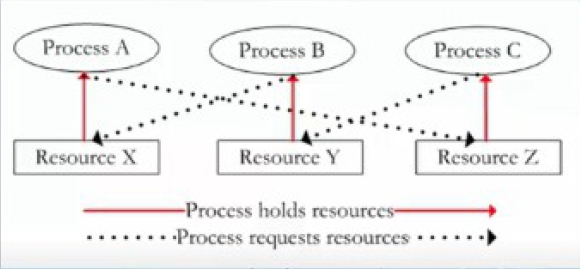
作業系統發生的死結(deadlock)也是類似的情況,處理元就像是車子,處理元掌握的資源就像車子占有的車道,處理元所需要的資源剛好掌握在別的處理元手上,而自己所占有的資源又剛好是別的處理元正需要的。多工的環境中容許多個程式同時執行,這可以看成是一種多個處理元同步執行的現象,同步會產生死結(deadlock)的處理問題,必須等資源得到之後才能繼續執行,假如所等待的資源無法取得,處理元就會一直處於阻絕的狀態。
死結的問題必須解決,而且最好能按照某些規則自動進行,處理的方式可以分成以下幾大類:
1. 預防(prevention):讓死結形成的條件無法同時成立,這樣死結就無法發生,防範於未然。
2. 避免(avoidance):先了解系統中資源將被使用的情況,以這樣的資訊來決定資源使用的順序,避免死結的發生。
3. 偵測(detection)與復原(recovery):容許死結發生,但是系統必須做經常性的死結偵測,在發現死結時復原為原來的狀態。
4. 自行解決(manual handling):不特別執行任何機制,在問題產生時想辦法解決,是最消極的做法。
Dijkstra在西元1968年提出所謂的deadly embrace的概念,這是發生在一群處理元之間的一種現象,每個處理元擁有至少一種資源,同時請求取得另外一種資源,可以這個資源剛好正被另一個暫停(blocked)中的處理元所占有,更剛好的是暫停的原因是所需要的資源被之前的處理元先占有了!
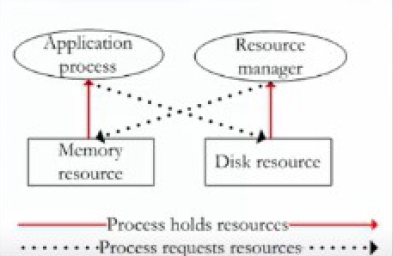
資源管理程式與作業系統同樣可能牽涉到死結的發生情況,假設一個大型的應用執行時先取得了大部分的主記憶體,這期間剛好磁碟分配管理程式被置換出(swap out)記憶體外,接下來應用程式需要使用某個磁碟空間,需要磁碟分配管理程式來處理,可是磁碟分配管理程式有又無法載入,這時候就會發生死結
可透過模型(model)來表示系統組成的資源分配狀況,以系統的狀態(state)來說,若是模型能夠表示出系統任一時刻的狀態,當然我們就能判定當時是否有死結發生。因此,在理論上可以為系統的狀態建立一個完整而正式的(formal)模型,在理論上為死結的處理發展出適當的預防、避免或是偵測的策略與方法,而實作上就會有很好的依據。

處理元通常透過一些系統呼叫來執行上述的動作,例如對於裝置進行的request( )與release( )呼叫、對於檔案進行的open( )與close( )呼叫,或是對記憶體進行的allocate( )與free( )呼叫。假如作業系統並沒有為特定的資源提供這一類的呼叫,則處理元可以透過semaphore的wait( )與signal( )操作,或是用mutex lock來控制資源的取得與釋出。
從實務上來看,只要是作業系統管理的資源,都會有系統的表格記錄資源的使用狀態,包括資源是否有空、或是目前擁有該資源的處理元,以及等待使用資源的處理元佇列。對於一個資源來說,等待使用它的處理元形成了一個處理元佇列,假如有一群處理元,其中每個處理元都等待著另一個資源,而這個資源剛好被同一群處理元內的某個處理元所占用,這時候就會形成死結了。
發生死結有4個必要條件,這4個條件同時存在才會發生死結:
1. 互斥(mutual exclusion) :至少有一個資源正被處理元獨占使用,換句話說,這個資源無法被一起共用,其他需要使用該資源的處理元必須等待。
2. 占有與等待(hold and wait) :處理元占有至少一個資源,同時等待另外一個被其他處理元占用的資源。
3. 循環等待(circular wait) :存在著一群處理元{P0,P1,‧‧‧,Pn},P0等著使用P1占用的資源,P1等著使用P2占用的資源,‧‧‧,Pn-1等著使用Pn占用的資源,Pn等著使用P0占用的資源。這就是所謂的循環等待的狀態。
4. 不間斷(no preemption) :資源的使用無法被中斷,必須由使用該資源的處理元主動釋出,所以必須等處理元完成工作。
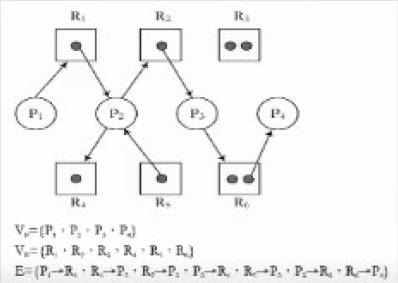
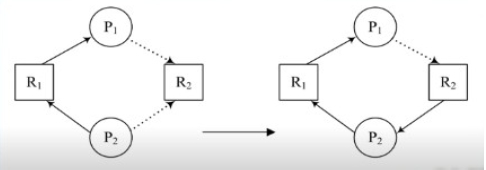
我們可以用有向圖形(directed graph)來精確地描述死結,這樣的圖型稱為系統資源分配圖(system resource-allocation graph),由處理元指向資源的箭頭表示該處理元對該資源的請求(request),稱為request edge,由資源指向處理元的箭頭代表該資源目前分配給該處理元,也稱為assignment edge
一般說來有下列3種處理死結的方法,UNIX與Windows作業系統都採用第3種方式,等於是將死結問題推給應用程式解決。
1. 透過協定(protocol)來預防或避免死結的發生,確定系統永遠不會進入死結的狀態(deadlock state)。
2. 允許系統進入死結的狀態,但是必須能夠偵測死結,回復系統。
3. 完全忽略有死結的問題。
系統中若是有死結發生,表示mutual exclusion、hold and wait、circular wait與no preemption等4種狀況同時發生了! 所以死結預防的策略就是確定至少有一種狀況不成立! 互斥(mutual exclusion)的狀況通常比較難去否定,所以死結預防通常會動其他3種狀況的腦筋。
1. 互斥(mutual exclusion) : 處理元分配得到某種資源的使用權以後,就有了完全的使用權利(exclusive use) ,其他的處理元無法再使用這種資源。有的資源原本就具有互斥的特性,無法避免,例如印表機就是很典型的無法分享的資源。唯讀的檔案(read-only files)則是可分享的資源,所以不必要求互斥。
2. 占有與等待(hold and wait) : 處理元可以占有某種資源同時請求使用另外一種資源。假如要避免這種情形發生,通常有兩種方式,一種是要求處理元在執行以前必須先取得所需要的資源,另外一種方式是要求處理元必須在沒有擁有任何資源的情況下才能請求使用資源。
3. 循環等待(circular wait) : 一個處理元p1擁有資源R1,請求使用資源R2。而剛好處理元p2擁有資源R2,請求使用資源R1。這就是循環等待。也有可能發生兩個以上的處理元形成循環等待的情況。要避免循環等待的發生可以採用下面的方法,先將所有的資源類型加以排序並且編號,然後要求處理元在請求使用資源時必須按照資源類型編號的遞增順序,例如處理元已經擁有編號1與3的資源類型,則接下來不能請求使用編號為2的資源類型,因為2小於3,理論上可以證明這樣能預防的發生循環等待。
4. 不間斷(no preemption) : 資源的釋出只能透過處理元自行發出的動作,無法由外界強制取得。這包括處理元請求使用資源的狀況,所以若是資源無法釋出,處理元也無法取消其請求。要避免這種情況可以要求無法取得資源的處理元先釋出自己擁有的資源,等於是中斷了這些資源的使用,對於這個處理元來說,這些釋出的資源都成為自己等待取得的資源。當然,假如擁有資源的處理元並沒有請求並等待其他的資源,我們不會要求該處理元釋出其已經擁有的資源。
死結的預防(prevention)限制處理元請求的送出,原則是確定死結形成的4個要件不會同時發生。不過可能產生的副作用是資源的使用率降低、系統的完成率(throughput)也降低。另外一種避免死結發生的方式是預先了解處理元對於資源的使用狀況,例如處理元將要使用資源的順序、以及將釋出資源的順序,則系統就能判定是否有進入死結狀態的可能性。
資源分配圖型演算法採用的是避免死結的策略,首先要加入預約使用的概念,假如處理元Pi將會使用資源Rj,則資源分配圖型中就要加入Pi→Rj的claim edge,以虛線來表示。
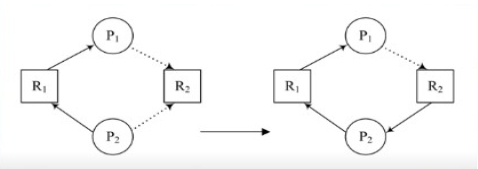
一旦R2分配給P2,則原先的claim edge就轉變成assignment edge。加入claim edge的概念以後,我們可以在處理元執行以前就把claim edge都加到資源分配圖型中,然後先檢查圖型中是否有迴路存在,假如沒有迴路存在才能確保未來不會發生死結。
死結避免方法的精神: 考量一組處理元與一組資源,系統的狀態決定於資源分配給處理元的方式,因此我們可以依照各種組合得到可能存在的系統狀態(system state)。假設我們用表格allocation來表示資源分配給處理元的情況,Allocation[i,j]的值代表Rj被Pi持有的數目,至於每個處理元可能需要某種資源的最大數目則以表格maxclaim來表示。
資源管理程式(resource manager)在資源可用的(available)情況下可以將資源分配給發出請求的處理元,資源管理程式可以判定在所有處理元都使用maxclaim數目的資源時,仍然存在request、allocation與deallocation的次序,不致發生死結。
從系統的狀態的角度來看死結的問題,簡單地說,我們會盡量避免系統有走向deadlock states的可能性。
班克演算法使用了以下幾種資料結構,這些資料結構記錄著系統的資源分配的狀態,n代表系統中處理元的數目,m代表資源類型的數目:
1. 可用的資源(available):假如Available[j]=k,則表示資源類型Rj中有k個資源目前為可以使用的狀態。陣列Available有m個元素。
2. 處理元的最大需求(max):Max是一個n×m的矩陣,表示每個處理元對於資源使用的最大需求,Max[i,j]=k表示處理元Pi最多會用k個Rj。
3. 分配的資源(allocation):Allocation是一個n×m的矩陣,代表目前分配給某處理元的資源數目,Allocation[i,j]=k表示k個Rj目前分配給處理元Pi。
4. 處理元剩餘的資源需求(need):Need是一個n×m的矩陣,代表處理元還需要使用的某種資源類型的數目,Need[i,j]=k表示處理元Pi還需要k個Rj類似的資源。從定義上來看,Need[i,j]=Max[i,j]-Allocation[i,j]。
舉例來說,系統有X、Y與Z共3種類型的資源,各有8個、9個與10個資源,目前系統有5個處理元,資料可以得到Available[2]=1,Max[0,0]=1,Max[4,2]=7,Allocation[1,2]=1,Allocation[3,1]=2,Need[2,2]=1。

系統必須從處理元的資源使用狀況與需求來分析是否所有的處理元都能順利執行完成,以圖的例子來看,我們先試著讓P0執行,所以需要再分配1個X與3個Z給P0,但是從Available來看無法做這樣的分配。假如是讓P2先執行,則只需要再分配1個Z,P2執行完成後,X、Y與Z分別剩下2、3與3個,最後找到P2→P3→P0→P1→P4的執行順序可以完成所有的處理元,所以目前系統還是在safe的狀態。
在資源分配出去之前也可以先做檢查,首先要確定處理元請求的資源數目小於等於需要的資源數目,也就是Need矩陣中對應的數目,否則就要發出錯誤訊息。另外,若是請求的資源數目大於剩下的資源數目也不行,這時間處理元必須等待。若是有足夠的資源數目可以分配,則假定資源分配下去,透過前面的演算法檢查系統是否在安全狀態,假如是的話,就可以將資源分配下去。
採用偵測與復原的策略可以讓資源的分配大膽一些,因為避免死結發生的方法只要碰到系統可能在不安全的狀態(unsafe state)下,就絕不會分配資源,其實不一定會造成死結。在偵測與復原的方法中,系統可以儘量地把資源分配出去,假如發現有處理元長久停滯,即可執行偵測演算法(detection algorithm),若是真正發生死結,只有使用復原(recovery)的方法把系統還原到沒有死結的狀態。
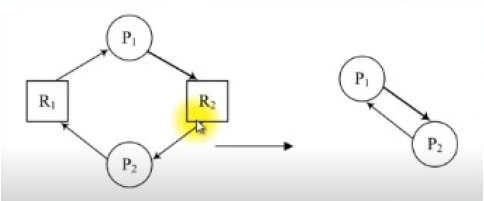
資源類型只有單一案例的情況: 首先要把資源分配圖型簡化成所謂的等待圖型(wait-for graph),亦即在資源分配圖型找出Pi→Rj且Rj→Pk的情況,然後將這兩個edge變成Pi→Pk單一的edge。
假如每種資源類型有多個資源,則前面等待圖型的死結偵測方式就不適用了,必須回歸到資料結構的使用,記錄系統資源使用與分配的情況,然後設計演算法從所記錄的資料中偵測是否會發生死結。
死結偵測的演算法發現有死結存在之後,有幾種處理的方式,其中一種是通知管理者來處理,另外一種則是讓系統透過復原來解決死結的問題。打破死結最直接的方式是終止一些處理元的執行,或是中斷某些資源的使用。執行偵測與復原勢必會耗損一些系統的資源,而且產生一些損失,因為原本完成的部分運算被還原了。

選擇中斷的處理元時還要考量一些因素:
1. 處理元的優先順序。
2. 處理元已經執行了多久?
3. 處理元使用了多少資源?資源是否容易中斷?
4. 處理元還需要多少資源才能繼續執行。
5. 有多少處理元需要中斷?
6. 處理元是批次作業還是互動的?
要透過資源的中斷來移除死結可以先選定一些資源、使其作業中斷(preempted),然後重新分配給其他處理元使用,一直到死結消失。



