我原本背景偏向數據分析與演算法,沒有影像辨識的經驗,因緣際會下,我不小心踏入了AR VR領域進行「人頭朝向辨識」。我本來以為我又要從零開始,不過這次發現我可以直接把過去的「數據分析」與「資料科學」技術直接搬過來用,而且效果還滿好的。
 https://jishuin.proginn.com/p/763bfbd29dcf
https://jishuin.proginn.com/p/763bfbd29dcf
令人意外的是,明明非常多人在做這個題目,但我查遍SCI期刊與網路上的做法,至今仍未發現用「數據分析」方法做這個題目的。對此我的猜想是,會做人頭朝向辨識的都以機器學習或者深度學習或者3D空間轉換的專家為主,而數據分析專家則可能都早被其他領域的人搶走了,很少流入影像辨識領域的吧,我可能是一個例外。
既然沒看到公開以「數據分析」方式來進行這個題目的,我就來插個旗子吧。剛好我這邊有一個很簡單且容易理解的實例,我就以這個實例來分享數據分析與資料科學家可能會對這個題目做些什麼。
「資料科學家」的工作目標就是要「從各種型態數據中擷取出有用的資訊進行應用」,而為了要達到上述這一句話需要學會非常多技術,「數據分析」算是一個「起手式」,從「起手式的起手式- 初步數據分析」之後分散出百千條作法與技術。至於如何決定分散去哪裡以及要使用何種技術,就是資料科學家需要準備好的專業,目前沒有SOP,所以能使用適合技術的資料科學家一定是高薪的。
釐清題目
那就進入主題吧。首先需要知道數據、目標、限制、資源?
以人頭朝向辨識來說,最開始的「數據」就是具有人頭的影像,「目標」就是要輸出這個人頭的朝向角度,至於「限制」,目前因為疫情的關係,攝影機拍到的人頭都是戴口罩的人頭,所以限制就是需要戴口罩情況下也要能夠辨識!而「資源」,目前有很多取得人臉或者肢體「特徵座標」(landmarks)的開源套件(這個階段一定要靠深度學習才可能做),使用這個開源套件讓我們可以從特徵座標開始進行題目,等於是縮小題目救了不會深度學習的資料科學家。
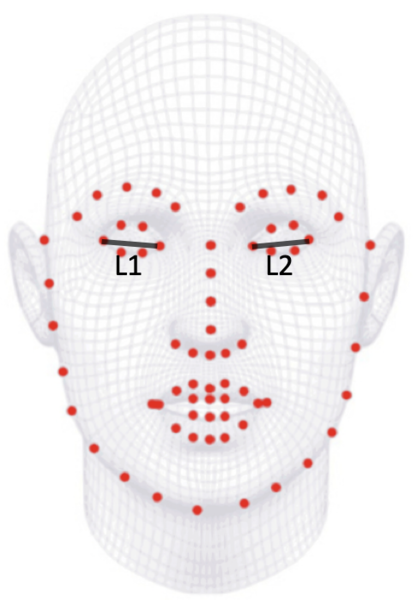
「所以我們現在的題目就是擁有「眼部以上」的特徵座標(因為鼻子與嘴巴被口罩遮住了),從這些座標就要計算出yaw(左右)角度。」
尋找方法
看起來好像題目不太複雜?但如果考慮人頭在攝影機的哪個方位後會發現問題也沒有這麼單純!不過因為我們要解問題就需要先簡化問題,所以就先固定攝影機都在人頭的正前方,也固定了之間的距離。有一個開源數據集“pointing04”就是針對人頭朝向辨識所建立的資料庫,裡面有15人,包含yaw(左右)與pitch(上下)角度之組合。不過我們現在問題只有看pitch=0情境下的yaw角,所以就只取數據集中pitch=0圖片。
有了數據集,就可以用開源套件取出圖片中人臉的特徵座標了,這邊使用Google的開源套件“mediapipe”來做這件事,每個人臉會取出468個特徵座標,其實特徵座標太多了,不過這邊只是DEMO而已。另外別忘了戴口罩區域是不能取用的,所以我們就只剩下眼部區域的特徵座標。
接下來問題就是要如何處理特徵座標了,不過想也知道人頭朝向並不會直接和座標直接相關,所以我們需要把「座標」經過「數據轉換」。這個步驟稱為「特徵擷取」(feature extraction),這個步驟的成功與否很可能大抵決定了之後模型的成功與否,而這部分與資料科學家的專業能力直接相關。
我這邊採用直覺的做法是先計算出座標與座標間的「長度」或「向量」,然而這樣轉換還不夠,因為長度會隨人頭與鏡頭之遠近而改變,向量也會隨人頭與鏡頭間之旋轉而改變,因此我再轉化一次,將長度與長度相除得到「長度比值」,將向量與向量求得「向量夾角」,如此一來,這兩種特徵就可以很適合用於人頭朝向的特徵了。
「在這個例子中,我經由觀察覺得「兩個眼睛的長度比值」會跟yaw角度有相關度。」
數據分析
既然懷疑「兩個眼睛的長度比值」這個feature和我們要辨識的yaw角度有相關,那就「把數據畫出來」看看吧!
我把數據集的15個人,取得特徵座標後,計算出兩眼距離L1與L2,接下來以長的除以短的得到一個大於1的比值,然後再分別畫出此feature與yaw角度二者之關係圖,就會得到下圖左:

建模(Modeling)
我們看到了這個feature還真的和yaw角度具有顯著相關!但是這樣存在一個問題,在同一個feature數值下,yaw可能是正的也可能是負的,這種情況我們可以直覺地用L1與L2比大小的方式來進行判別,但是這樣的作法如果是要用來做「機器學習」的話就會很不方便。所以我把這個feature的半邊乘以-1,如上圖中,這樣我們就能以正負號來判斷朝左還是朝右了。但是光光是半邊乘以-1,這樣的數據會出現「不連續」現象,這對於機器學習或者一般建模而言還是很不方便,因此我再把兩邊數據都往中心位移1,就成為上圖右。
「到這個階段,漂亮的「線性關係」出現了!」
這時候就可以直接以「簡單線性迴歸」去模擬二變數間的關係了!以這筆數據我們得到了下述關係式:
yaw = -73 * feature
在做線性回歸時我刻意讓常數項等於0,因為這條線性回歸理論上應該要過零點。另外,我們觀察到在45度的數據已有散開現象,且開始有非線性關係,因此我在做線性回歸時只有取-30度~+30度間的數據來做回歸。
辨識
到目前為止,我們已經可以做yaw角度辨識了!當一張影像或者影片流的每一幀進來,先透過mediapipe獲取人臉特徵座標,這邊就只有取“4”個座標點而已,也就是兩個眼睛的四個眼角。接著這四個座標經由轉換得到我們前述的“feature”,然後“feature”再經過我們的線性模型而輸出yaw角度!
測試
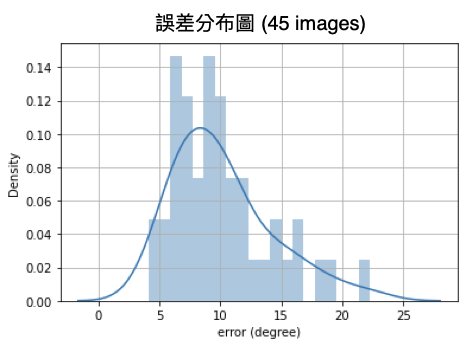
那麼以這個模型所獲得的辨識結果如何呢?我將pointing04數據集保留了45張影像當作測試數據,經由訓練數據建模的辨識誤差如圖所示,其平均誤差為10.16度(-45度 ~ +45度)。其實以這麼簡單的方法能獲得這樣的效果,我覺得已經很好了!
即時攝影辨識
即時攝影的辨識就是將每一幀的影像分別以上述模型計算出yaw角度而形成數據流。然而,難免經由演算法的一系列流程後,yaw角度值有不太穩定的結果發生,於是我對影像辨識的yaw數值做了「移動平均」計算,此舉可以平衡掉演算過程中出值結果不穩定的問題。
延伸題目
上述過程只描述了人頭相對於相機「定點」的角度偵測,那如果人頭存在於相機前方的1D範圍區域,或者甚至2D範圍區域呢?這個還是可以用類似的數據分析方法來完成唷!
另外我們之所以可以用這麼簡單的數據就得到還不錯的yaw角辨識表現,是因為人臉具有高度的左右對稱性。那如果我們今天的題目是要加上pitch(上下)角度辨識呢?這部分我使用數據分析方式來建模,還未見到有好效果的,直到我使用「機器學習SVR」才獲得不錯的效果,不過這邊不會討論。
實作的時刻
總之以上使用了一個很簡單的概念,不過要在沒見過類似作法的情況下從無中生有的提出一個概念,就未必簡單,因為可能中間嘗試過無數的失敗。而且從概念到實作之間也還是有一段距離,所以通常說真正的“會”是以實際實作出來時才算數的,那就趕快實做看看吧!
限會員,要發表迴響,請先登入


