


這種實際上有點微彎的車牌你也不能說它就是違法的!要監理單位為此開罰單?當然不可能!如果能像停車場出入口一樣正面拍攝要辨識也沒問題的!但是像這種停車柱的斜視角度呢?每個字元的寬度其實是不一樣的!變化的規律還是非線性的!
如果剛好每個字元目標都很完整也是還好的!就是不管寬高每個字各自調整到字模大小就辨識出來了!但實務上遠端的字元就是非常歪斜,解析度太低之下當然都是很破碎的!即使我努力將車牌附近的影像切割出來做了幾何校正,大概也只能做到如下圖:
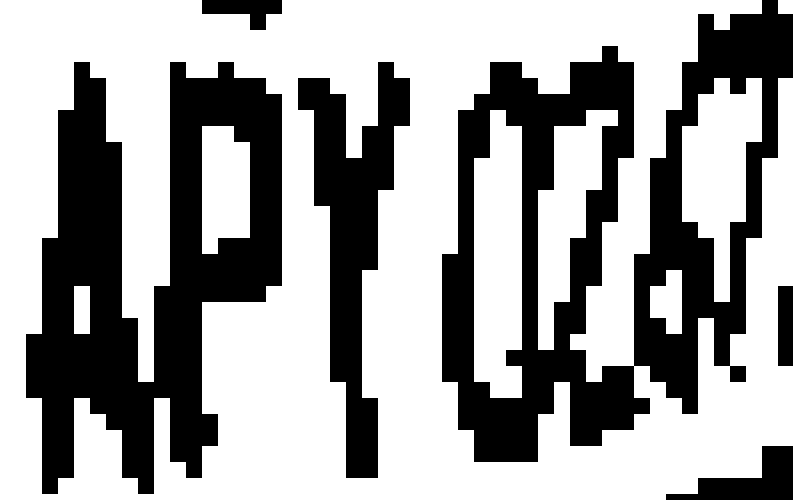
通常到此階段我都必須假設每個字元的寬度與高度是一樣的!以此例來說,APY0四個字元是原本就可以辨識的,267三個字就必須一一搜尋切割才可能挖出來了!但如果我堅持這幾個字的寬度與高度也應該和APY0一樣?那當然無法成功!因為事實上就不是一樣嘛!
所以在這個模糊混沌的小範圍內,就必須做類似CNN的多尺度掃描(Multi-Scale Convolution)了!譬如前面幾個可辨識字元的寬度是7畫素,後面那個267的亂集團就必須用5或6畫素寬度也都試試看了!甚至字元位置還會因為車牌彎曲而逐漸上下移動!但是CNN的概念就是全圖掃描嘛!把所有可能性都試試總是可以找到的!只是要多花點時間而已!
當然最終我還是可以克服萬難將這個車牌辨識出來的!真的困難到這個程度我也被迫使用CNN的地毯式搜索了!但是還好,需要做這麼麻煩計算的範圍很小,計算量增加不算太大,還是不需要呼叫GPU幫忙,速度也不會被明顯拖慢的!
所以簡單說,我應付不完整的OCR辨識結果,就是先假設未辨識出來的字元也應該與已辨識出來的字元一樣大!啟用CNN的固定大小矩陣掃描目標的計算模式,就可以鎖定破碎或沾連的字元了!但是碰到如上這種特殊狀況呢?假設字元大小一致,硬切出來的字元符合度當然是很低的!那就放寬CNN掃描的寬高與位置設定,做更全面的CNN掃描了!
習慣找公式來套用的玩家或專家一定覺得我的做法很不美觀?但是這確實是最合理的解題方式!我認為其實人的視覺智慧應該也是這樣思考的!為了解數學題其實我們都會建立很多假設,但是這些假設必須符合物理事實!同一個車牌內的字元大小確實一樣!但是經過車牌的彎曲與斜視角度後拍攝的結果就是不一樣!我們辨識的是影像嘛!數學模式當然必須因應調整!
所以你還覺得這麼複雜的邏輯,可以用大量資料深度學習就能自動產生嗎?如果你還是堅持相信可以用深度學習達到這種辨識功能?我只能說你的AI妄想症真的病得不輕了!
